
游戏客户端面经(自整理版)
岗位:游戏客户端开发
C++
1. 深拷贝和浅拷贝
深拷贝和浅拷贝的核心区别在于:拷贝时到底是只复制一层引用,还是把引用指向的内容也一起复制出一份新的。
浅拷贝是什么
定义 浅拷贝是指按字节或按成员逐个复制对象的值。对于指针类型的成员,只复制指针本身(即地址),而不复制指针所指向的内容。 在 C++ 中,如果用户没有显式定义拷贝构造函数和拷贝赋值运算符,编译器会自动生成默认版本,这些默认版本执行的就是浅拷贝。
特点
- 执行速度快,实现简单
- 多个对象共享同一份动态资源
- 容易引发重复释放(double free)或悬垂指针(dangling pointer)问题
深拷贝是什么
定义 深拷贝是指不仅复制对象的成员变量本身,对于指针类型的成员,还会重新分配内存,并将原指针所指向的内容复制到新分配的内存中。这样每个对象都拥有自己独立的资源副本,互不影响。
特点
- 避免了资源重复释放和意外共享
- 实现相对复杂,需要显式定义拷贝构造函数和拷贝赋值运算符
- 性能开销较大(涉及内存分配和数据复制)
2. 编译器默认生成的拷贝构造(拷贝赋值)的语义是什么?
易错:编译器默认做浅拷贝。
主要语义是:对每个非静态成员执行逐一拷贝。
- 对于内置类型(包括指针、算术类型等):直接进行按位复制(即浅拷贝)。例如指针成员只复制地址,不复制所指向的内容。
- 对于类类型成员:调用该成员类型的拷贝构造函数(对于拷贝构造)或拷贝赋值运算符(对于拷贝赋值)。这意味着拷贝的深浅由成员类型自身的拷贝语义决定。如果成员是
std::vector或std::string等 RAII 类型,它们自己的拷贝构造是深拷贝,那么该成员也会被深拷贝。 - 对于数组成员:对每个元素逐一拷贝,元素本身再按上述规则处理。
- 对于继承的基类子对象:调用基类的拷贝构造函数(或拷贝赋值运算符),同样遵循基类的拷贝语义。
关键点: 默认拷贝操作不是笼统的“浅拷贝”,而是“成员逐一拷贝”。所谓“浅拷贝风险”主要出现在类中直接持有原始指针、C风格数组或其它需要显式管理资源的成员时,因为指针会被按位复制,导致多个对象共享同一块资源,进而引发双重释放或悬垂指针。
因此:
- 如果一个类的所有成员都是 RAII 类型(如
std::vector、智能指针、std::string),且这些类型正确实现了拷贝语义,那么默认的拷贝构造/赋值就是安全的,无需自定义。 - 如果一个类直接管理资源(如通过
new分配的内存),则必须遵循规则三/五,显式定义拷贝构造、拷贝赋值和析构函数(以及移动操作)来实现深拷贝,或禁用拷贝(例如使用= delete)。
补充区别(拷贝构造 vs 拷贝赋值):
- 拷贝构造发生在对象创建时(如初始化、传参、返回),新对象尚不存在,直接按成员拷贝。
- 拷贝赋值发生在对象已存在时,默认生成的赋值运算符会先进行自赋值检查(虽然默认版本通常不做检查,但规范实现中应避免自赋值问题),然后依次对每个非静态成员调用赋值操作(对于类类型成员调用其
operator=,对于内置类型直接复制)。但默认的赋值运算符不会自动释放原有资源,因此如果类管理资源,仍需要显式实现。
3. 如何对基类指针做深拷贝?
核心解决方案:提供虚克隆函数
在基类中声明一个纯虚函数 clone(),每个派生类重写该函数,返回自身类型的深拷贝(通常以基类指针形式返回)。这样,通过基类指针调用 clone() 就能动态地完成正确的深拷贝。
1 |
|
注意这里代码返回类型为 unique_ptr<Base> ,这是可以的,函数返回值本身就是右值,不会涉及到拷贝赋值,只有移动语义。
4. 讲一讲智能指针?
智能指针是 C++ 中管理动态内存的工具,通过 RAII 自动释放资源,避免内存泄漏和野指针。
unique_ptr:
- 独占所有权:不可拷贝,只能移动。
- 常用操作:
std::make_unique<T>(args)创建,reset()释放,release()放弃所有权。 - 适合作为类的成员或容器元素,默认删除器为
delete,可定制。
shared_ptr :
- 共享所有权:引用计数,最后一个
shared_ptr销毁时释放资源。 - 常用操作:
std::make_shared<T>(args)创建(一次内存分配),use_count()查看引用计数。 - 注意循环引用:两个
shared_ptr互相持有对方,导致引用计数永不归零,内存泄漏。
weak_ptr:
- 弱引用:不增加引用计数,用于打破循环引用。
- 不能直接访问资源,需通过
lock()获取shared_ptr,若资源已释放则返回空。 - 常用于观察者模式、缓存等场景。
智能指针可传入自定义删除器(其实就是个函数对象),用于管理非 new 分配的资源(如文件句柄、malloc 等):
1 | auto deleter = [](FILE* f) { fclose(f); }; |
5. 智能指针如何处理数组?
unique_ptr 对数组类型有模板特化,使用 T[] 作为模板参数。使用 new T[] 分配,默认删除器自动调用 delete[]。
1 | template<typename T> |
shared_ptr 在C++17前需自定义删除器调用 delete[]。C++17 起:std::shared_ptr 同样支持数组类型 std::shared_ptr<int[]>,并提供 operator[],默认删除器为 delete[]。
6. const存储周期
6.1 全局/静态 const 对象
1 | const int g1 = 5; // 常量表达式初始化 |
6.2 局部 const 对象
1 | void f() |
6.3 类中的 const 成员
1 | class A |
| 变量类型 | 初始化表达式 | 存储位置 | 初始化/存储时机 |
|---|---|---|---|
全局/静态 const |
常量表达式 | 只读数据段(.rodata)或被编译器优化掉 | 编译期 |
全局/静态 const |
运行时计算 | 全局数据段(.data) | 编译期分配空间,程序启动时(运行时)初始化 |
局部 const |
常量表达式 | 栈,但通常被编译器优化掉 | 运行时(进入作用域时),但值在编译期已知 |
局部 const |
运行时计算 | 栈 | 运行时(进入作用域时) |
类 const 成员 |
- | 随对象(栈、堆或全局数据区) | 运行时(对象被构造时) |
这里需要注意,如果不显式声明 extern,那么全局 const 变量是内部链接的。这点和C不一样。
7. 静态变量和全局变量在使用上的区别
| 特性 | 全局变量 | 静态全局变量 | 静态局部变量 |
|---|---|---|---|
| 作用域(Scope) | 全局 | 文件 | 函数/代码块 |
| 链接性(Linkage) | 外部链接(External) | 内部链接(Internal) | 无链接 |
| 跨文件访问 | 可以(通过extern声明) | 不可以 | 不可以 |
| 初始化时机 | 程序启动时(main之前) | 程序启动时(main之前) | 第一次执行到该行代码时 |
| 初始化顺序 | 不固定(不同文件之间) | 不固定(不同文件之间) | 由代码执行流决定 |
| 生命周期 | 整个程序运行期间 | 整个程序运行期间 | 整个程序运行期间 |
8. C++字符串存在哪个区域
在C++中,“字符串”这个词可以指代不同类型的实体,它们的存储位置也因此不同。
8.1 字符串字面量(String Literal)-> 存在常量区
const char* str = "Hello, World!"; 这里就是个字符串字面量。它具有以下特点:
- 存储位置:它被存储在程序内存的只读数据区(Read-only Data Segment),这块区域通常被称为常量区。
- 只读性:任何试图修改它的行为都是未定义行为(Undefined Behavior),通常会导致程序崩溃。
- 共享性:编译器可能会对相同的字符串字面量进行优化,让它们共享同一块内存地址,以节省空间。
结论:C风格的字符串字面量,存储在常量区.rodata。
8.2 std::string 对象 -> 栈与堆的结合体
它的内存管理比较复杂:
- 对象本身(管理结构):
std::string对象本身包含了指向字符串数据的指针、字符串长度、容量等管理信息。如果这个对象是作为函数内的局部变量声明的,那么这个对象本身是存储在栈上的。 - 字符串数据:
std::string内部管理的字符数据,通常存储在堆区。当创建std::string对象时,它会在堆上动态创建一块内存来存放字符串内容。当std::string对象被销毁时,它的析构函数会自动释放这个内存。
特殊情况:小字符串优化(Small String Optimization,SSO)
现代C++标准库的 std::string 实现普遍采用一种叫做小字符串优化的技术。
- 原理:如果字符串非常短(例如小于16或24个字节),
std::string会直接将字符串数据存储在对象内部,而不是从堆神奇内存。 - 目的:避免小字符串频繁地进行堆内存分配和释放带来的性能开销。
结论:std::string 对象本身通常在栈上,其管理的字符数据通常在堆上,但对于短字符,由于SSO的存在,数据也可能直接在栈上。
8.3 动态分配的字符串 -> 存在于堆区
如果你使用 new 关键字来动态创建字符串,那么无论是 std::string 对象还是C风格的字符数组,它们都会被分配在堆区。
1 | std::string* heap_str_obj = new std::string("I am on the heap"); |
结论:使用 new 创建的任何类型的字符串,其主要数据都存储在堆区。
9. 为什么STL实现要采用自己的内存管理器?为什么实现分为一级和二级分配器?
一、为什么STL要采用自己的内存管理器?
当我们编写程序时,通常通过 new/delete 或 malloc/free 进行内存的申请与释放。这会存在一些问题:
- 频繁调用性能较低:系统的内存申请和释放需要进入OS的内核态或调用底层系统调用接口,这会带来较大的性能开销。
- 容易产生内存碎片:这里主要只的是堆上的内存碎片,它发生在进程的虚拟地址空间内,而不是物理内存。频繁调用malloc和free会在这个空间切出不同大小的块,并导致:已释放的块散落各处,形成许多大小不一的空闲块;下次申请大块内存时,可能所有空闲块都太小,即使总空闲空间足够,也无法分配——这就是堆的外部碎片。
为了解决这些问题,STL设计了一套内存管理机制,即 Allocator(分配器)。
通过自定义分配器,可以:
- 减少频繁的系统调用,批量地从系统中申请较大的内存块,一次性管理;
- 避免频繁的小块内存的申请和释放,显著降低性能开销;
- 降低内存碎片的产生概率,提高程序整体的效率。
二、STL为什么要分为一级分配器和二级分配器?
这种分层设计是为了更灵活、更高效地管理不同规模的内存块:
① 一级分配器(第一级配置器)
- 又称为 malloc allocator (malloc分配器)
- 事实上就是直接调用系统的malloc/free,直接与系统交互,负责处理较大的内存分配请求。
- 通常申请较大的内存块(例如超过128字节或256字节,具体实现可能不同)
- 优势:大内存申请较少,且不频繁,直接向系统申请简单高效,易于维护
② 二级分配器(第二级配置器)
- 又称为 内存池(memory pool)分配器或 自由链表(free-list)分配器。
- 它针对小块内存进行特殊优化(8、16、24、…、128字节)
- 其设计思想为:
- 事先从系统一次性批量地申请较大的内存块,并将这些大块内存进行切分,组成自由链表
- 用户在申请小块内存时,直接从内存池分配
- 用户释放小块内存时,直接归还到对应的free list中,以便复用。
- 优势:极大减少了内存分配和释放的系统调用次数,提升了小对象的内存分配效率,显著降低内存碎片。
10. 你会如何实现内存泄漏检测功能?
10.1 重载 new/delete 记录分配信息
原理
在全局或类级别重载 operator new 和 operator delete,在分配时记录指针、大小、文件、行号等信息,在释放时删除记录。程序结束时,输出未释放的记录。
实现要点
- 使用一个线程安全的容器(如
std::unordered_map<void*, AllocationInfo>)存储分配信息。 - 通过宏将
new替换为new(__FILE__, __LINE__),传递文件名和行号。 - 重载
operator new的带参数版本,接收const char* file, int line,并存储。 - 重载对应的
operator delete以移除记录。
10.2 自定义分配器
在项目中使用自定义内存分配器(如继承 std::allocator),在分配时记录。这种方式更适合大型项目,可以统一管理内存,并与智能指针结合。
11. C++中的默认构造函数做了什么?
在 C++ 中,默认构造函数是指不需要参数即可调用的构造函数(可以是无参构造函数,也可以是所有参数都有默认值的构造函数)。
编译器何时合成默认构造函数
- 如果用户没有声明任何构造函数,编译器会隐式声明一个默认构造函数。当该类的对象被需要默认构造时(例如定义对象
T obj;,或使用new T等),编译器会隐式定义它。 - 如果用户声明了其他构造函数(包括拷贝/移动构造函数)但没有声明默认构造函数,编译器不会再隐式生成默认构造函数。此时,若需要默认构造,将导致编译错误。
编译器合成的默认构造函数做了什么
它按以下顺序执行初始化:
- 调用基类的默认构造函数(若基类有默认构造函数)。
- 调用非静态数据成员的默认构造函数(按声明顺序),对成员进行默认初始化。
- 对于内置类型(如
int,float, 指针等),不做任何初始化(保留未定义的值),除非:- 该成员在声明时提供了类内初始值(C++11 起,如
int x = 0;),则使用该值初始化。 - 该成员是 const 或引用,且未提供类内初始值,则必须由用户显式初始化,否则编译错误。
- 该成员在声明时提供了类内初始值(C++11 起,如
简单来说:合成的默认构造函数负责对子对象(基类、成员)进行默认初始化,但不会自动对内置类型清零。
用户定义的默认构造函数
用户可以显式定义默认构造函数(包括使用 =default 或 =delete)。=default 强制编译器生成默认构造函数(行为与隐式合成一致),=delete 则禁止默认构造。
12. 讲一下 std::condition_variable 的逻辑?
https://en.cppreference.com/w/cpp/thread/condition_variable.html
一、概述
std::condition_variable 是一个同步原语,需要配合 std::mutex 使用。它的作用是:让一个或多个线程阻塞等待,直到另一个线程修改了共享变量,并通知条件变量。
文档中特别强调了两点使用规则:
- 修改共享变量的线程必须:
- 先获取互斥锁
- 在持有锁的情况下修改共享变量
- 之后可以调用
notify_one或notify_all(释放锁前后调用都可以,但通常建议在释放锁后调用,避免唤醒的线程立即再次阻塞)
- 等待共享变量的线程必须:
- 使用
std::unique_lock<std::mutex>获取同一个互斥锁 - 然后调用
wait/wait_for/wait_until。这些函数会原子地释放锁并挂起线程,直到被唤醒;唤醒后会重新获得锁再返回
- 使用
💡 为什么不能只用原子变量? 文档特意说明:即使共享变量是原子的,也必须用互斥锁来保证等待线程能看到正确的修改。因为条件变量的等待和唤醒需要与锁配合才能避免竞态条件。
我问了AI,这里必须要搭配互斥量的原因是为了保证“检查条件 + 进入等待”这个组合操作的原子性,这个原子性只能通过锁来保证。
举个例子:
1 | std::condition_variable cv; |
上面代码有一个明显的竞态条件:
- 等待线程执行到 ①,发现
ready == false,准备进入等待。 - 在它执行到 ② 之前(比如刚检查完,还没获取锁和调用
wait),通知线程被调度执行。 - 通知线程执行 ③ 和 ④,将
ready设为true并发送通知。 - 此时等待线程还没有进入
wait,所以这个通知丢失了。 - 等待线程继续执行,获取锁,进入
wait,但之后再也没有人通知它了,它永远阻塞。
即使 ready 是原子的,也无法阻止这种丢失唤醒,因为问题的根源在于“检查标志”和“进入等待”这两个操作不是原子的,它们之间有空隙。
二、虚假唤醒
虚假唤醒(spurious wakeup)是指线程在没有被其他线程通过 notify_one 或 notify_all 显式通知的情况下,从等待状态中苏醒。
1 | std::mutex mtx; |
13. C++的封装有什么好处?
封装是面向对象编程的三大特性之一,它将数据和对数据的操作捆绑在一起,并对外隐藏内部实现细节。在 C++ 中,封装主要通过 class 和访问控制符(public、protected、private)来实现。封装的好处主要体现在以下几个方面:
1. 隐藏实现细节,降低复杂度
- 只暴露必要的接口,使用者无需关心内部实现,只需通过公开的成员函数进行操作,降低了认知负担。
- 例如,一个
BankAccount类只提供deposit和withdraw方法,而内部余额的存储和校验逻辑完全隐藏,使用者不必了解底层细节。
2. 增强代码安全性
- 通过将数据成员设为
private,防止外部直接修改,保证对象状态的一致性。 - 可以在成员函数中加入边界检查、日志、权限验证等控制逻辑,避免非法操作。
- 例如,设置
setAge(int age)时检查age > 0,避免对象进入无效状态。
3. 提高模块化与可维护性
- 封装将类的内部实现与外部使用分离,修改内部实现时只要保持接口不变,外部代码无需改动,降低了模块间的耦合度。
- 例如,将原来的数组存储改为
std::vector,只要get/set接口不变,所有调用者都不受影响。
4. 支持代码复用与扩展
- 封装后的类可以作为独立组件被其他模块使用,通过继承和多态进一步扩展功能。
- 由于接口稳定,可以方便地替换实现(如不同的底层算法),而使用者无感知。
5. 有助于团队协作
- 清晰的接口定义使得不同开发人员可以并行工作:一方负责实现内部细节,另一方只需了解接口文档即可使用,减少沟通成本。
6. 便于调试与测试
- 封装将错误隔离在类内部,可以通过单元测试单独验证类的功能,定位问题更快。
14. 如何通过动态链接实现热插拔?
__declspec 是 Microsoft Visual C++ 编译器中用于指定存储类属性的扩展关键字。它允许开发者为函数、类、变量等添加特定的特性,其中最常用的是 dllexport 和 dllimport,用于控制动态链接库(DLL)中符号的导出与导入。
一、__declspec(dllexport) 导出符号
在 DLL 项目中,当你希望将某个函数、类或变量暴露给其他可执行文件或 DLL 使用时,需要将其导出。使用 __declspec(dllexport) 告诉编译器将该符号放入 DLL 的导出表,从而让外部模块可以通过 LoadLibrary / GetProcAddress 或隐式链接找到它。
1 | // MathDLL.cpp |
编译后,Add 函数会出现在 DLL 的导出表中。
类导出:
1 | __declspec(dllexport) class Calculator { |
这样整个类的所有公有成员函数都会被导出(但私有成员不会被导出,外部也无法访问)。
二、__declspec(dllimport) 导入符号
在使用 DLL 的模块(如主程序)中,需要声明要使用的符号是从外部 DLL 导入的。__declspec(dllimport) 告诉编译器该符号在另一个模块中定义,从而生成更高效的代码(直接通过导入表调用,而非间接跳转)。
1 | // main.cpp |
如果不加 dllimport,编译器可能无法确定符号的来源,从而产生错误或生成效率较低的代码。
三、使用条件宏统一头文件
为了让同一个头文件既能用于 DLL 的编译(导出)又能用于使用方的编译(导入),通常采用一个条件宏:
1 | // Calculator.h |
- 在 DLL 项目中,定义
CALCULATOR_EXPORTS宏,则CALCULATOR_API展开为__declspec(dllexport)。 - 在使用方项目中,不定义该宏,则展开为
__declspec(dllimport)。
这样只需包含同一个头文件,即可正确处理导出/导入。
四、热插拔示例
我们来实现一个基于 __declspec(dllexport/dllimport) 的日志类示例,演示动态链接库的热插拔。该示例包含:
- 共享头文件
LoggerAPI.h,定义导出宏、日志类接口和导出函数声明。 - 版本1 DLL:简单的控制台输出日志。
- 版本2 DLL:增强版,同时输出到控制台和文件。
- 主程序:动态加载 DLL,实现热插拔(先加载版本1,再切换到版本2)。
TODO
五、注意事项
1. 导出类能否包含内联成员函数?
可以。导出类(__declspec(dllexport))中可以有内联函数,但需要注意:
- 内联函数会在调用处展开,不会从 DLL 中导出符号。如果调用方(主程序)包含了头文件,则内联函数会直接编译进主程序的代码中。
- 这本身不会导致链接错误,但如果内联函数访问了 DLL 内部的私有成员(如成员变量),由于这些成员变量在 DLL 和主程序中的布局可能不同(如编译选项、内存对齐差异),可能导致未定义行为。
- 因此,跨 DLL 边界的类,通常避免内联函数,或者只使用简单的 getter/setter 且不依赖内部布局。
2. 导出类能否包含虚函数?
可以。导出类完全支持虚函数,虚函数表由 DLL 生成,主程序通过对象指针调用时会正确跳转到 DLL 中的实现。但是:
- 如果主程序使用隐式链接(即通过导入库
.lib链接),那么主程序可以像使用普通类一样使用导出类,包括调用虚函数。 - 如果主程序使用显式加载(
LoadLibrary+GetProcAddress)实现热插拔,则不能直接使用导出类,因为虚函数表地址在编译期就被固定,无法运行时替换。这时必须使用纯虚接口(抽象基类) + 工厂函数的方式。
3. 对于导出类,只导出里面的成员函数?
不准确。当你在整个类前加上 __declspec(dllexport) 时,整个类的所有非内联成员函数、静态成员变量、虚函数表等都会被导出。如果你想只导出部分函数,可以:
- 不对整个类导出,而是对需要导出的成员函数逐个添加
__declspec(dllexport)。 - 但这样外部无法直接创建该类的对象(因为构造函数未导出),通常搭配工厂函数使用。
六、隐式链接(运行前动态链接)和显式链接(运行时动态链接)
一、隐式链接(运行前动态链接)
特点:DLL 在程序启动时由操作系统自动加载,程序可以直接调用 DLL 中的函数或使用导出类,就像使用静态库一样。
注意点:
- 需要导入库(.lib):编译时必须链接到 DLL 对应的
.lib文件,否则链接器会报“无法解析的外部符号”。 - 使用
__declspec(dllimport)修饰:头文件中声明的函数、类应标记为__declspec(dllimport),以便编译器生成更高效的调用代码。 - 导出类:整个类导出时,可以包含内联函数和虚函数,但需确保主程序与 DLL 使用相同的编译器、运行时库、内存对齐等设置,否则可能因布局不一致导致崩溃。
- 加载时机:DLL 在程序启动时加载,若 DLL 缺失或依赖缺失,程序会直接启动失败。
- 无法热插拔:DLL 的符号在编译期绑定,运行时无法动态卸载或替换。
- 调用开销:函数调用通过导入地址表(IAT)间接跳转,但开销极小,通常可忽略。
二、显式链接(运行时动态链接)
特点:程序在运行时通过 LoadLibrary 主动加载 DLL,通过 GetProcAddress 获取函数地址,再通过函数指针调用。通常用于插件系统、热更新等场景。
注意点:
- 无需导入库:编译时不依赖
.lib文件,所有 DLL 功能通过函数指针调用,因此不会出现“无法解析的外部符号”链接错误。 - 必须导出为 C 函数(或使用
extern "C"):由于GetProcAddress按名字查找,为避免 C++ 名字修饰(name mangling),被获取的函数应使用extern "C"声明,或使用.def文件指定导出名。 - 类导出困难:不能直接导出整个类供主程序使用(因为类的成员函数调用需要编译器知道布局,而主程序未链接导入库)。通常使用纯虚接口(抽象基类) + 工厂函数模式,通过虚函数实现多态。
- 手动管理 DLL 生命周期:需要调用
FreeLibrary卸载 DLL,并确保在卸载前销毁所有从该 DLL 创建的对象,否则可能导致悬垂指针或资源泄漏。 - 函数指针类型转换:从
GetProcAddress获取的是裸地址,需要转换为正确的函数指针类型,注意类型安全。 - 错误处理:必须检查
LoadLibrary和GetProcAddress的返回值,妥善处理 DLL 缺失、函数未找到等情况。 - 支持热插拔:可以随时卸载旧 DLL、加载新 DLL,实现动态替换功能,但需保证接口一致。
15. STL各个容器的sizeof?一个个分析?
我们在g++下得到以下结果:
1 | std::array<int, 10> : 40 |
array是对原生数组的封装,没有虚函数,没有额外指针,内部直接包含int[10],大小 =10 * sizeof(int) = 40std::vector包含三个指针,每个指针 8 字节,共 24 字节。_First:指向已分配内存的起始。_Last:指向最后一个有效元素之后。_End:指向已分配内存的末尾。
std::deque:
1 | struct _Deque_impl_data |
按你现在的 GCC/libstdc++ 实现,deque 内部关键数据是:
_M_map:指向“指针数组”的指针,8字节_M_map_size:size_t,8字节_M_start:起始迭代器_M_finish:结束迭代器
而 _Deque_iterator 里又有 4 个指针成员:
在 64 位下每个指针是 8 字节,所以一个迭代器大小是32。总共加起来80
std::list:有一个哨兵头节点,包含两个指针next和prev,总共16字节,加上缓存的size,一共24字节。std::forward_list:单向链表,只保存指向第一个节点的指针(8 字节),没有大小成员std::string:看 string 的话,你这套 GCC 14 + libstdc++(x64)里,sizeof(std::string) 通常是 32,原因是对象本体大致是这三块:- 数据指针包装 大小 8 字节 说明:内部有一个 _Alloc_hider,默认分配器是空类型,利用 EBO 后基本只剩一个指针 _M_p。
- 当前长度 大小 8 字节 说明:_M_string_length 是 size_t。
- 一个联合体 大小 16 字节 说明:联合体在这两个成员里取较大者:
- 本地小缓冲区 _M_local_buf(char 时是 16 个字节,含结尾 ‘\0’)
- 堆容量字段 _M_allocated_capacity(8 字节)
set/map/multi***:
- _Rb_tree_node_base = 32 包含 1 个颜色字段 + 3 个指针(父,左儿子,右儿子)。 在 x64 下 3 个指针是 3×8=24,再加颜色和填充,最终到 32。
- _Rb_tree_header = 40 它是:
- 一个 _Rb_tree_node_base(32)
- 一个 size_t 节点计数(8)
所以 32+8=40。
- 比较器包装是 1 字节 std::less
是空类型,但“作为成员”存在于包装结构里,结构体最小也要占 1 字节(不能为 0)。 - 最终对齐到 8 字节 _M_impl 的有效内容约为 40+1=4140+1=41 字节。 对象按 8 字节对齐,向上补齐到 48。
在g++中核心为:
1 | struct _Rb_tree_impl |
这段继承,本质是把红黑树实现拆成三块职责,组合成一个实现体:
- 分配器基类:_Node_allocator
- 比较器基类:_Rb_tree_key_compare<_Key_compare>
- 树状态基类:_Rb_tree_header
在你当前环境(x64, GCC 14 的 libstdc++)里,我刚实测到这些大小:
- sizeof(std::allocator<std::_Rb_tree_node
>) = 1 - sizeof(std::_Rb_tree_key_compare<std::less
>) = 1 - sizeof(std::_Rb_tree_header) = 40
- 另外,sizeof(std::_Rb_tree_node_base) = 32(这是 header 里面的核心子对象)
下面逐个解释。
- _Node_allocator 代表什么
- 作用:负责节点内存分配/释放(allocate/deallocate),也参与构造/析构节点值。
- 内部内容:默认分配器 std::allocator 通常是空类型,没有状态字段。
- 为什么实测是 1:空类作为独立对象至少占 1 字节。
- 但作为基类时通常可被 EBO(空基类优化)压到 0 额外开销。
- _Rb_tree_key_compare<_Key_compare> 代表什么
- 作用:保存键比较器对象,用于所有有序比较(例如 lower_bound、插入定位、旋转后次序判断)。
- 内部内容:一个成员 _M_key_compare。
- 你当前用的比较器是 std::less
,它是空类型,所以这个包装类型实测也是 1 字节。 - 同样,作为基类时常能被 EBO 吃掉,不单独增加对象体积。
- 如果你换成带状态比较器(比如里面有 int mode),这一块会真实变大。
- _Rb_tree_header 代表什么
- 作用:保存整棵树的“全局状态”。
- 内部成员:
- _M_header,类型是 _Rb_tree_node_base
- _M_node_count,类型是 size_t
- _M_header 不是普通数据节点,而是哨兵头节点,维护:
- parent 指向根
- left 指向最左节点(begin 常数时间)
- right 指向最右节点
- color 字段(实现里也放着)
- 大小推导:
- _Rb_tree_node_base = 32(颜色 + 3 个指针 + 对齐填充)
- size_t = 8
- 所以 _Rb_tree_header = 32 + 8 = 40
为什么设计成多重继承
- 目的就是把“可能为空”的部分(分配器、比较器)放到基类,利用 EBO 降低对象体积。
- 真正稳定占空间的是 _Rb_tree_header 这 40 字节,因为它存的是树的结构状态,不能为空。
和你之前看到 48 字节的关系
对于 set
底层树对象来说,主体是 header 的 40 字节。 再加上比较器/分配器相关基类与整体对齐,最终落到 48 字节(你之前实测一致)。
关键点:默认比较器和默认分配器几乎“不带状态”,所以增量主要来自对齐,而不是大字段。
unordered**:真正占空间的是_Hashtable。你说的六个成员,本质上是把哈希表拆成三层:- 桶层:定位入口
- 节点链层:存实际元素
- 扩容策略层:控制什么时候重排
下面按这六个成员逐个讲它在实现里“怎么参与操作”。
- _M_buckets(桶数组指针)
- 角色:哈希表的一级索引。
- 它指向一个“桶指针数组”,每个桶位里存的不是元素本身,而是链表关联信息。
- 查找流程里先算 hash(key),再用 range-hash 得到 bucket index,然后用 [_M_bucketsindex] 找到该桶链起点附近。
- 你可以把它理解成“目录页”。
- _M_bucket_count(桶数)
- 角色:决定索引空间大小。
- 参与 bucket 映射:index = H(hash_code, _M_bucket_count)(常见是 % bucket_count 或策略变体)。
- 负载因子计算也依赖它:load_factor = element_count / bucket_count。
- rehash 后它会更新,旧桶映射全部失效,元素重新分桶。
- _M_before_begin(全局前置哨兵)
- 角色:统一单链节点组织,简化插入/删除边界条件。
- 内部本质是一个 _Hash_node_base,只有
next指针。 - 哈希表节点在实现里是“链式节点”;有了这个前置哨兵,处理“第一个节点”时不用写特殊分支。
- _M_begin() 实际就是看 _M_before_begin._M_nxt,所以全局 begin 能常数时间获得。
- _M_element_count(元素计数)
- 角色:O(1) 的 size() 与 rehash 判定输入。
- 每次 insert 成功会 ++,erase 成功会 –。
- 扩容策略函数会用 (bucket_count, element_count, n_insert) 判断是否需要 rehash。
- 这让容器不需要遍历节点去算大小。
- _M_rehash_policy(重哈希策略对象)
- 角色:控制“何时扩容、扩到多少桶”。
- 默认策略里关键状态是:
max_load_factor(阈值)next_resize(下一次触发点)
- 插入前后会调用策略判断:如果预计超过阈值,返回“需要 rehash + 新桶数”。
- 它把“扩容决策”从哈希表主逻辑里解耦出来,便于不同策略(质数桶/2幂桶)切换。
- _M_single_bucket(单桶优化指针)
- 角色:小表优化与移动语义优化。
- 初始/极小状态下,不立刻分配真正桶数组,而让 _M_buckets 指到这个“内嵌单桶”。
- 好处:
- 减少小容器的堆分配
- 空表/小表移动更容易保持 noexcept 路径
- 当需要更多桶时才分配真实桶数组并切换 _M_buckets。
把它们串成一次插入过程:
- 用 _M_rehash_policy + _M_element_count + _M_bucket_count 判断是否先 rehash。
- 若要扩容:分配新桶数组,更新 _M_buckets/_M_bucket_count,重挂节点。
- 计算新元素桶下标,落到 [_M_bucketsidx] 对应链。
- 通过 _M_before_begin/桶链前驱关系把新节点挂入。
- _M_element_count++。
一次查找过程:
- 算 hash -> bucket index(依赖 _M_bucket_count)。
- 从 [_M_bucketsidx] 进入该桶链。
- 链上逐个比较键(hash/equal),命中返回。
核心理解一句话: 这六个成员正好覆盖了哈希表运行所需的最小状态集: “索引入口(buckets)+ 链式存储锚点(before_begin)+ 容量与数量(bucket_count/element_count)+ 扩容控制(rehash_policy)+ 小表优化(single_bucket)”。
stack/queue,内部是dequepriority_queue,内部包含一个vector和一个比较器对象。
16. static 的语义?
如果面试现场要完整回答,可以这样说: static的作用主要有两类,一个是控制对象的生命周期,一个是控制名字的可见范围或归属关系。修饰变量时,如果是局部变量,会让它变成静态局部变量,生命周期变成整个程序运行期间,但作用域仍然只在函数内部;如果修饰全局变量,会把它限制在当前源文件可见;如果修饰类成员变量,表示它属于类本身,所有对象共享同一份。 修饰函数时,如果是普通函数,表示这个函数只在当前源文件可见;如果是类的静态成员函数,表示它属于类而不属于对象,没有this指针,不能直接访问非静态成员。所以本质上,static修饰变量更多是在控制存多久、谁共享、谁能看见”,修饰函数更多是在控制谁能调用、调它需不需要对象”。
17. 虚函数也会被隐藏吗?
在 C++ 中,虚函数的覆盖(override)要求派生类中的函数与基类虚函数的函数签名完全相同(包括参数类型、个数以及 const 限定符)。如果派生类中定义了与基类虚函数同名但参数列表不同的函数,那么:
- 派生类的函数不会覆盖基类的虚函数,而是会隐藏基类中所有同名的函数(包括基类的虚函数及其重载版本)。
- 此时,通过基类指针或引用调用该函数时,调用的仍然是基类的虚函数版本(动态绑定到基类),而不会调用派生类中的函数。
- 派生类中的函数如果也标记了
virtual,它仍然是一个独立的虚函数(因为它有自己不同的签名),但不会与基类虚函数形成覆盖关系,虚函数表中会为它单独分配一个条目。
总结:会,因为是两个独立的虚函数!
1 |
|
如果子类的不是虚函数呢?如果函数签名一样,那即便不声明 virtual ,它也是虚函数。
如果签名不一样,那么可以推导一下,两个函数是独立的。子类的虚表内对应的虚函数是父类的实现:
1 |
|
18. 带捕获列表的lambda能被默认构造吗?
在 C++ 中,带捕获列表的 lambda 表达式生成的闭包类型(closure type)不具有默认构造函数。这是标准明确规定的,因为捕获的变量需要在构造闭包对象时初始化,无法通过默认构造来提供这些捕获值。
具体规则
- 无捕获的 lambda(C++11 ~ C++17):闭包类型也没有默认构造函数(只有拷贝/移动构造),直到 C++20 才为无捕获的 lambda 增加了默认构造函数。
- 有捕获的 lambda(任何 C++ 版本):闭包类型始终没有默认构造函数。捕获列表中的变量(值捕获或引用捕获)必须在创建 lambda 对象时初始化,因此只能通过 lambda 表达式本身或从另一个闭包对象拷贝/移动构造。
1 | // 无捕获(C++20 之前) |
为什么这样设计?
- lambda 表达式本质上是一个匿名结构体,捕获的变量成为其成员变量。
- 对于值捕获,成员变量需要被初始化;对于引用捕获,成员变量是引用,也必须在构造时绑定。
- 编译器无法为这些成员生成合理的默认值,因此默认构造函数被删除。
19. 右值不能取地址,但是右值真的没地址吗?
- 纯右值(prvalue):没有“持久”的地址,你不能用
&取地址,但它在求值过程中会有一个临时对象,这个临时对象在内存中是有地址的(只是语言层面禁止你直接获取)。 - 将亡值(xvalue):有地址,可以取地址(因为它通常是对某个对象的右值引用)。
所以“右值不能取地址”的说法是不准确的,更准确的说法是:纯右值(prvalue)不能取地址,而将亡值(xvalue)可以取地址。
C++11 之后,右值被分为两类:
- 纯右值(Pure rvalue, prvalue):例如字面量
42、算术表达式a+b、函数返回的非引用类型、临时对象Foo()等。 - 将亡值(eXpiring value, xvalue):例如
std::move(obj)、static_cast<T&&>(obj)、成员函数返回右值引用等。
1. 纯右值(prvalue):不能取地址,但临时对象有地址
对纯右值应用取地址符 & 会导致编译错误:
1 | int* p = &42; // 错误:不能对右值取地址 |
但纯右值在表达式求值过程中会生成一个临时对象(除非编译器优化掉)。这个临时对象在内存中占据某个地址,只是你无法通过 & 获取它,因为临时对象具有短暂的生命周期,取地址可能导致悬垂指针。例如:
1 | const int& r = 42; // 临时对象被延长生命周期 |
2. 将亡值(xvalue):可以取地址
将亡值本质上是一个引用(右值引用),它指向一个已有对象,因此可以取地址:
1 | int x = 10; |
同样,返回右值引用的函数调用结果也是将亡值,可以取地址:
1 | int&& foo() { int a=1; return std::move(a); } // 危险示例,仅示意 |
3. 为什么会有这种区别?
- 纯右值:代表一个“即将消失的临时值”,它的生命周期通常只在一个完整表达式内(除非绑定到 const 左值引用或右值引用以延长)。语言不允许取地址是为了防止程序员意外持有指向临时对象的指针,导致使用后对象已销毁。
- 将亡值:代表一个“可被移动的对象”,它仍然是一个“具名”对象的引用(或者移动后的对象),因此它拥有身份(identity),可以取地址。
20. 左值引用和右值引用可以相互转换吗
左值引用和右值引用之间不能隐式相互转换,但可以通过 std::move 将左值转换为右值引用;而具名的右值引用变量本身是左值,可以隐式转换为左值引用。此外,const 左值引用可以绑定到右值(纯右值或将亡值),这是一种特殊的转换,常用于延长临时对象生命周期。
21. 模板能不能声明和定义分开写
可以。如果你提前知道模板会用到的所有类型,可以在 .cpp 中显式实例化,从而隐藏实现。
在我的软光栅项目中,我根据不同的FragmentShader的策略实例化不同的Rasterizer,模板声明如下:
1 | // Rasterizer.h |
定义则在 Rasterizer.cpp 中。为了在 Pipeline 中能正确使用各种 Policy 的 Rasterizer ,需要给出各个 Policy 的 Rasterizer 的实现,这里在定义中显式告诉编译器进行编译:
1 | // 显式实例化模板 |
这样使用方就可以在链接的时候找到对应实例化模板类的实现。
22. 内存对齐
1 | struct A{ |
答案是16。面试时被面试官误导答成12了。(米哈游我cnm)
1 | A 的内存布局(12 字节): |
23. 如果我改了一行代码,但是编译牵扯到了很多文件,你觉得是为什么?
修改的是头文件(最常见原因)
- 头文件包含链:如果修改的是一个被广泛包含的头文件(例如公共配置头、基础类型定义头、工具宏头),那么所有直接
#include它的源文件,以及所有间接包含它的源文件,都需要重新编译。 - 内联函数 / 模板定义:内联函数和模板的完整定义通常必须放在头文件中。修改它们会导致所有调用该函数或实例化该模板的源文件重新编译。
- 类的修改:修改一个类的成员变量(增加、删除、改变顺序)或虚函数表布局,会改变类的内存布局,因此任何使用该类的源文件都必须重编。
修改影响了宏定义
如果修改的文件中定义了宏,且这个宏被大量文件使用(例如用于条件编译、调试开关、平台适配),那么这些文件在宏值改变后需要重新编译。
如何减少这种影响?
- 前向声明:在头文件中尽量使用前向声明,避免包含不必要的头文件。
- PIMPL 惯用法(Pointer to IMPLementation):将类的实现细节隐藏到独立的实现类中,头文件只暴露接口,减少编译依赖。
- 拆分头文件:将一个庞大的头文件拆分为多个小的、职责单一的头文件。
- 使用
export(已废弃)或模块(C++20 Modules):C++20 的模块系统可以从根本上避免头文件包含导致的重复编译问题。 - 合理设计预编译头:只将非常稳定的、极少修改的头文件放入预编译头。
- 依赖反转:通过抽象接口降低具体实现的依赖传播。
24. 介绍一下CAS?
CAS全称是 Compare And Swap,它做的事情很简单:
- 先比较某个内存位置当前值是否等于“预期值”
- 如果相等,就把它改成“新值”
- 如果不相等,就不改
整个过程由硬件保证是原子的。
25. 如何明确区分左值和右值?
cppref:
Each C++ expression (an operator with its operands, a literal, a variable name, etc.) is characterized by two independent properties: a type and a value category. Each expression has some non-reference type, and each expression belongs to exactly one of the three primary value categories: prvalue, xvalue, and lvalue.
a glvalue (“generalized” lvalue) is an expression whose evaluation determines the identity of an object or function;
a prvalue (“pure” rvalue) is an expression whose evaluation
computes the value of an operand of a built-in operator (such prvalue has no result object), or
initializes an object (such prvalue is said to have a result object).
The result object may be a variable, an object created by new-expression, a temporary created by temporary materialization, or a member thereof. Note that non-void discarded expressions have a result object (the materialized temporary). Also, every class and array prvalue has a result object except when it is the operand of decltype;
- an xvalue (an “eXpiring” value) is a glvalue that denotes an object whose resources can be reused;
- an lvalue is a glvalue that is not an xvalue;
面试的时候咱就说能不能直接取地址算了。
408
1. 进程通信的方式
匿名管道
- 特点:半双工(数据单向流动),用于父子进程或具有亲缘关系的进程之间。
- 实现:
pipe(int fd[2]),fd[0]读端,fd[1]写端。 - 优点:简单,内核管理缓冲。
- 缺点:只适用于亲缘进程,无格式字节流,数据量有限。
命名管道(FIFO)
- 特点:在文件系统中有路径名,可用于任意进程间通信(需有访问权限)。
- 实现:
mkfifo()创建,然后像普通文件一样open、read、write。 - 优点:支持无亲缘关系的进程,遵循文件权限管理。
- 缺点:仍为半双工,写入和读取可能阻塞,需自行处理同步。
信号
- 特点:异步通知机制,用于进程间发送简单事件(如
SIGINT、SIGTERM)。 - 实现:
kill()发送信号,signal()或sigaction()注册处理函数。 - 优点:轻量,快速,适合处理异常事件。
- 缺点:信息量少,不能携带大量数据;处理时机不确定;部分信号不可靠(传统信号可能丢失,现代实时信号支持排队)。
消息队列
- 特点:消息链表存储于内核,进程通过消息队列收发带有类型的数据块。
- 实现:System V 消息队列(
msgget、msgsnd、msgrcv)或 POSIX 消息队列(mq_open、mq_send、mq_receive)。 - 优点:支持多对多通信,消息有类型可实现优先级,可持久化(System V 可随内核持续)。
- 缺点:系统资源有限,需手动清理,传输大小有限制。
共享内存
- 特点:多个进程直接映射同一块物理内存区域,数据无需复制,速度最快。
- 实现:System V(
shmget、shmat、shmdt)或 POSIX(shm_open、mmap)。 - 优点:极高效率,适合大量数据交换。
- 缺点:需要配合同步机制(如信号量)防止竞态条件,本身不提供同步;管理复杂,易产生死锁或数据不一致。
套接字(Socket)
- 特点:最通用的 IPC 方式,支持本机不同进程(Unix Domain Socket)和不同主机(网络 Socket)。
- 实现:
socket()创建,bind、listen、accept、connect、send/recv等。 - 优点:跨主机通信,支持字节流(TCP)和数据报(UDP),功能强大。
- 缺点:相对于其他 IPC 稍复杂,开销较大(网络协议栈)。
2. TCP和UDP区别
TCP:面向连接,保证按序交付
UDP:无连接,最大努力交付
| 比较维度 | TCP | UDP |
|---|---|---|
| 连接方式 | 面向连接,需要建立连接(三次握手、四次挥手) | 无连接,不需要建立连接 |
| 传输方式 | 字节流传输,不保留应用层消息边界,可能会造成粘包 | 数据报传输,保留消息边界 |
| 可靠性 | 可靠传输,确保数据有序、不丢失、不重复 | 不保证数据传输可靠性,可能发生丢包或乱序 |
| 流量控制 | 具备流量控制机制,可防止网络拥塞 | 无流量控制机制 |
| 拥塞控制 | 具有拥塞控制功能,动态调整传输速率 | 无拥塞控制机制 |
| 传输速度 | 相对较慢,由于连接管理和重传机制引入延迟 | 相对较快 |
| 头部开销 | 头部较大,通常至少20字节 | 头部较小,仅8字节 |
| 应用场景 | 高可靠性应用,如文件传输、网页浏览等 | 对时延要求高、丢包容忍的应用,如视频、音频、在线游戏等 |
| 错误检测 | 采用校验和、序列号等机制实现错误检测和恢复 | 仅使用校验和进行基本错误检测 |
3. 计算机大端和小端有什么应用
大端:高位字节在前。小端:低位字节在前。
大端应用:
- 网络字节序,TCP/IP协议栈规定,所有在网络上传输的二进制数据都必须采用大端字节序。这应该是用于统一在不同端序主机之间的消息同步的一致性。
- 标准文件格式:例如JPEG、PNG等图像文件都是大端序。
小端应用:
在现代处理器设计中占主导地位,其应用主要体现在硬件层面的计算效率上。
- 处理器计算效率:计算机在算术运算时,通常从最低位开始。由于最低位字节存放在最低地址,处理器可以直接从该地址开始读取数据并立即开始计算,无需进行地址调整。
- 普遍性:Intel x86架构占市场主导地位,小端序成为主导标准。
4. 并发和并行的区别?
说到多线程编程,就不得不提并行和并发,多线程是实现并发和并行的一种手段。
- 并行是指两个或多个独立的操作同时进行。
- 并发是指一个时间段内执行多个操作。
在单核时代,多个线程是并发的,在一个时间段内轮流执行;在多核时代,多个线程可以实现真正的并行,在多核上真正独立的并行执行。例如现在常见的4核4线程可以并行4个线程;4核8线程则使用了超线程技术,把一个物理核模拟为2个逻辑核心,可以并行8个线程。
5. 生产者消费者模型
5.1 生产者消费者模型简介
生产者和消费者问题是线程模型中的经典问题:生产者和消费者在同一时间段内共用同一个存储空间,生产者往存储空间中添加产品,消费者从存储空间中取走产品;当存储空间为空时,消费者阻塞,当存储空间满时,生产者阻塞。
简单来说,这个模型是由两类线程构成:
- 生产者线程:“生产”产品,并把产品放到一个队列里;
- 消费者线程:“消费”产品,具体是从队列中取出产品。
为什么使用生产者消费者模型?
在多线程开发当中,如果生产者处理速度很快,而消费者处理速度很慢,那么生产者就必须等待消费者处理完,才能继续生产数据,否则新生产的数据也没有地方存放;同样的道理,如果消费者的处理能力大于生产者,那么消费者就必须等待生产者,不然没有数据消费者也没办法消费。
为了达到生产者生产数据和消费者消费数据之间的平衡,就需要一个缓冲区用来存储生产者生产的数据,所以就引入了生产者-消费者模式。
5.2 实现
1 | std::queue<std::pair<int, int>> q; |
主要在于对于 std::condition_variable 的 notify 。
6. 系统调用和普通函数调用的区别是什么?
7. 进程的虚拟空间中的内核区的作用?
8. HTTP和HTTPS的区别
详细说明
- 加密方式
- HTTP 使用明文传输,任何中间节点(路由器、代理、ISP)都可以读取内容。
- HTTPS 通过混合加密:非对称加密(RSA/ECDHE)交换对称密钥,对称加密(AES)加密实际数据,并提供数字签名保证完整性。
- 证书验证 HTTPS 服务器需持有由受信任的证书颁发机构(CA)签发的数字证书。客户端(浏览器)会验证证书的合法性,防止中间人伪造服务器。
- 连接建立
- HTTP 在 TCP 三次握手后直接发送请求。
- HTTPS 在 TCP 握手后还需进行 TLS 握手(约 2 个 RTT),协商加密套件、验证证书、交换密钥。
- 性能影响 HTTPS 额外的握手和加解密会消耗更多 CPU 和延迟,但现代硬件和优化(如会话复用、TLS 1.3 的 0-RTT)已大幅减轻开销。
总结
- HTTP:简单、快速,但不安全,适用于公开的非敏感信息。
- HTTPS:安全、可信,适用于任何需要保护隐私和完整性的场景,已成为现代 Web 的标配。
面试加分点:可以提及 HSTS(强制浏览器使用 HTTPS)、混合内容(HTTPS 页面中引用 HTTP 资源会不安全)、TLS 握手流程 等。
9. 说说局部性?如何编写局部性良好的程序?
图形学
1. 渲染管线
(1)应用程序阶段,该阶段主要是在软件层面上执行的一些工作,包括空间加速算法、视锥剔除、碰撞检测、动画物理模拟等。大体逻辑是:执行视锥剔除,查询出可能需要绘制的图元并生成渲染数据,设置渲染状态和绑定各种Shader参数,调用DrawCall,进入到下一个阶段,GPU渲染管线。
(2)几何阶段,包含顶点着色、投影变换、裁剪和屏幕映射阶段。
注意,虽然在RTR4中几何阶段将顶点着色和投影变化分开了,但这两者都是在顶点着色器中完成的,为了方便理解我们可以统一称为顶点处理阶段。
顶点处理阶段:这个阶段会执行顶点变换和顶点着色的工作。通过模型矩阵、观察矩阵和投影矩阵(也就是MVP矩阵)计算出顶点在裁剪空间下的位置(clip space),以便后续阶段转化为标准化设备坐标系(NDC)下的位置。也可能会计算出顶点的法线(需要有法线变换矩阵)和纹理坐标等。同时,在这个阶段也可能会进行顶点的着色计算,如平面着色 (Flat Shading)和高洛德着色 (Gouraud Shading)都是在顶点着色器中进行着色计算。因为这个阶段是完全可控制的,因此执行什么样的操作由程序员来决定。(此外,在顶点处理阶段的末尾,还有一些可选的阶段,包括曲面细分(tessellation)、几何着色(geometry shading)和流输出(stream output),此处不详细描述)
裁剪阶段:对部分不在视体内部的图元进行裁剪。这部分是几乎完全由硬件控制的,因此没必要详细描述,至于为什么有了视锥剔除,到这个阶段还需要进行一次裁剪,可参考这个问题为什么在ndc归一化坐标已经包含了视锥体剔除功能的情况下 还需要视锥体裁剪? - 知乎 (zhihu.com)。简单来说就是两次裁剪的粒度不同,前者是在物体对象层面的,一般对对象的包围盒做剔除,剔除掉不在视锥体内的物体,NDC裁剪是在三角形层面做的,裁剪掉不在屏幕内的像素。
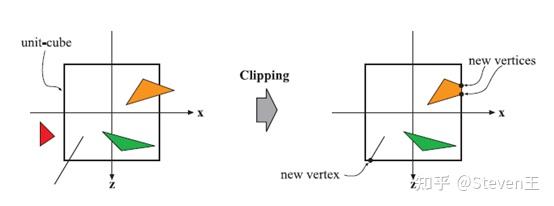
- 屏幕映射阶段:主要目的是将之前步骤得到的坐标映射到对应的屏幕坐标系上。
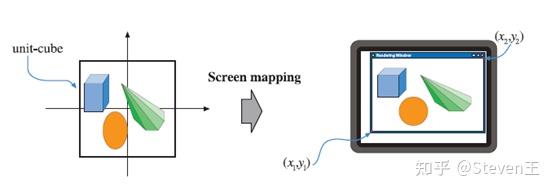
(3)光栅化阶段,包含三角形设置和三角形遍历阶段。
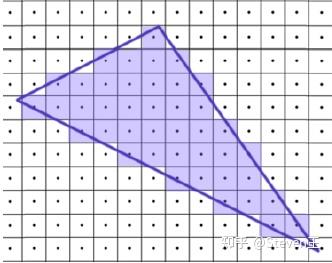
三角形设置(图元装配),计算出三角形的一些重要数据(如三条边的方程、深度值等)以供三角形遍历阶段使用,这些数据同样可用于各种着色数据的插值。
三角形遍历,找到哪些像素被三角形所覆盖,并对这些像素的属性值进行插值。通过判断像素的中心采样点是否被三角形覆盖来决定该像素是否要生成片段。通过三角形三个顶点的属性数据,插值得到每个像素的属性值。此外透视校正插值也在这个阶段执行。
这两个阶段是完全硬件控制的,不可进行任何操作。
(4)像素处理阶段,包括像素着色和测试合并。
像素着色,进行光照计算和阴影处理,决定屏幕像素的最终颜色。各种复杂的着色模型、光照计算都是在这个阶段完成。
测试合并,包括各种测试和混合操作,如裁剪测试、透明测试、模板测试、深度测试以及色彩混合等。经过了测试合并阶段,并存到帧缓冲的像素值,才是最终呈现在屏幕上的图像。
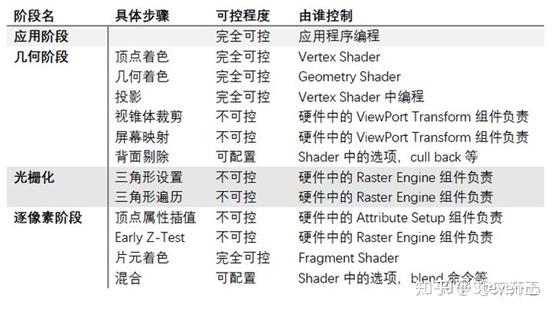
(5)各个阶段的可控性
2. PBR是什么?如何在实时渲染内实现PBR材质?
PBR包括的东西其实很多,这里主要讲RTR里的PBR材质
2.1 Microfacet BRDF
微表面模型(microfacet model) 是一种基于物理的局部光照模型,它假设物体的表面是凹凸不平的,宏观的表面由许多微小的平面(即微表面)构成,光线在每个微平面上发生理想镜面反射或折射。
由微表面模型定义的 BRDF 如下: $$ f_r(\omega_i, \omega_o) = \dfrac{F(\omega_i,h)G(\omega_i, \omega_o,h)D(h)}{4(\omega_i \cdot n)(\omega_o \cdot n)}. $$ 这里的 h 是入射和出射方向的半程向量。
2.1.1 Fresnel Term
菲涅耳项(Fresnel term) 描述了景物表面反射光线的比例依赖于光线的入射角和偏振这一现象,它告诉我们有百分之多少的能量会被反射出来。可以采用石里克近似(Schlick’s approximation)。
不太理解,看公式可以知道菲涅尔项只和入射角有关,但是很多教程都拿视角方向做例子,视角方向不是出射方向吗?
2.1.2 Normal Distribution Function(法线分布函数)
决定这一项的是不同微表面朝向的法线分布;当朝向比较集中的时候会得到Glossy的结果,如果朝向特别集中指向时认为是specular的,当分布杂乱无章时候,因此认为表面也非常复杂,得到的结果也就类似diffuse的。
可以有不同模型来描述法线分布。
- Beckmann模型:
$$ D(h) = \dfrac{e^{-\frac{\tan^2 \theta_h}{\alpha^2}}}{\pi \alpha^2 \cos^4 \theta_h}. $$
Games202里说的很形象:定义在Slope Space上的高斯分布。这里的 α 是roughness of the surface,θh 是半角和法线的夹角。
- GGX模型:更加long tail
2.1.3 Shadowing-Masking Term
阴影遮蔽项(shadowing-masking term) 又称几何项(geometry term),是光能由于微表面之间相互遮挡而衰减的系数。
- 当光线入射方向或观察方向几乎垂直于景物表面时,微表面之间差不多没有相互遮挡,几何项接近于 1;
- 当光线入射方向或观察方向几乎平行于景物表面、接近于掠射(grazinf angle)时,微表面之间相互遮挡的程度很大,几何项接近于 0。
The Smith shadowing-masking term:解耦入射和出射的几何遮挡项: G(i, o, h) ≈ G(i, h)G(o, h). 针对Beckmann或者GGX的法线分布所推导出的G项是不同的
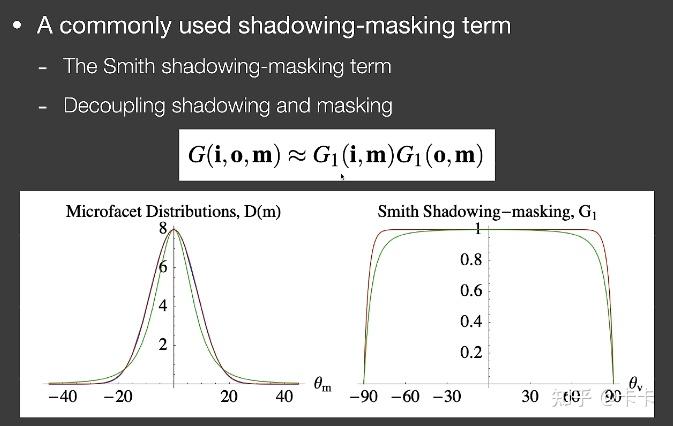
2.1.4 Kulla-Conty近似
测试结果发现当粗糙度越大时能量损失越多,导致着色变暗了。当微表面越粗糙,意味着自遮挡越严重会导致光线多次反弹,由于之前算法是只算一次光线反弹,所以当有多次光线反弹时就会导致能量丢失。
3. 讲一下环境光照?
IBL(Image-Based Lighting)是指根据环境光照图,在不考虑可见性 V(p, ωi) 的条件下直接着色给定点 p 的技术,相应的绘制方程如下: Lo(p, ωo) = ∫Ω+Li(p, ωi)fr(p, ωi, ωo)cos θidωi. 为了求解绘制积分,可以使用蒙特卡罗方法抽样环境光入射方向进行近似,但是为了让蒙特卡罗方法收敛,可能需要抽样大量的环境光入射方向样本,这将耗费大量的计算资源。因此需要优化。
首先,在实时渲染中,存在如下重要的估算定积分方法,将两个函数乘积的定积分拆解成两个函数定积分的乘积: $$ \int_{\Omega} f(x)g(x) \mathrm{d}x \approx \dfrac{\int_{\Omega_G} f(x)\mathrm{d}x}{\int_{\Omega_G} \mathrm{d}x} \cdot \int_\Omega g(x)\mathrm{d}x. $$ 假如被积函数较为平滑(例如漫反射材质的 BRDF),或者支撑集较小(例如光源相对不多时直接采样光源所用的可见性函数),则在实时渲染中认为该估计基本成立。因此,分离求和方法(the split sum)认为 BRDF 在求解定积分时可以被拆解出来,于是绘制方程变成了如下形式: $$ \begin{aligned} L_o(p, \omega_o) &= \int_{\Omega^+} L_i(p, \omega_i) f_r(p, \omega_i, \omega_o) \cos \theta_i \mathrm{d}\omega_i \\ &\approx \dfrac{\int_{\Omega_{f_r}} L_i(p, \omega_i)\mathrm{d}\omega_i}{\int_{\Omega_{f_r}}\mathrm{d}\omega_i} \int_{\Omega^+} f_r(p, \omega_i, \omega_o) \cos \theta_i \mathrm{d}\omega_i. \end{aligned} $$
3.1 Split Sum第一阶段
对于前一部分的积分 $\dfrac{\int_{\Omega_{f_r}} L_i(p, \omega_i)\mathrm{d}\omega_i}{\int_{\Omega_{f_r}}\mathrm{d}\omega_i}$,它相当于对环境光照图施加了均值滤波,而滤波卷积核的尺寸取决于 BRDF 的支撑集。于是,当着色给定点时,根据理想镜面反射方向查询预滤波后的环境光照图,就相当于同时查询了以理想镜面反射方向为中心的区域内的环境光照,便不需要抽样了。
可以选取不同尺寸的滤波卷积核,预计算环境光照图的图像金字塔,即 mipmap;在着色时,根据 BRDF 得到合适的滤波卷积核的尺寸,可以方便地从相应的层级或通过三线性插值得到环境光照。

3.2 Split Sum第二阶段
对于后一步的积分 ∫Ω+fr(p, ωi, ωo)cos θidωi,可以根据所有可能的参数进行预计算,或者使用 LTC 方法(Linearly Transformed Cosines)。假设这里的BRDF我们采用的微表面模型,可以对菲涅尔项进行石里克近似(Schlick’s approximation): F(θ) = R0 + (1 − R0)(1 − cos θ)5. 那么将后一步的积分进一步拆解: $$ \begin{aligned} \int_{\Omega^+} f_r(p, \omega_i, \omega_o) \cos \theta_i \mathrm{d}\omega_i &\approx \int_{\Omega^+}\dfrac{f_r(p, \omega_i, \omega_o)}{F(\theta_i)}[R_0+ (1 - R_0)(1 - \cos \theta)^5] \cos \theta_i \mathrm{d}\omega_i\\ &=R_0 \int_{\Omega^+}\dfrac{f_r(p, \omega_i, \omega_o)}{F(\theta_i)}[1 - (1-\cos\theta)^5] \mathrm{d}\omega_i + \int_{\Omega^+}\dfrac{f_r(p, \omega_i, \omega_o)}{F(\theta_i)}(1-\cos\theta)^5\cos \theta_i \mathrm{d}\omega_i. \end{aligned} $$ 这样就把底色 R0 去除掉了,剩下的BRDF项可以用一个预计算的2D Texture得到,考虑维度为roughness和余弦角。
3.3 PRT(Precomputed Radiance Transfer,预计算辐射亮度传输)
PRT(precomputed radiance transfer,预计算辐射亮度传输)的核心思想是假设场景中的只有光照会发生变化,将绘制方程的被积函数拆分成光照(lighting)和光线传输(light transport)这两部分,并分别预计算两者的纹理图像,再把图像从空间域转换到频域,最终把着色时绘制方程中的定积分计算转换成向量的点积,或者转换成向量与矩阵的乘法。
3.3.1 预计算光照(Lighting)和光线传输(Light transport)
PRT 将绘制方程的被积函数拆分成光照(lighting)和光线传输(light transport)这两部分,分别预计算而得到两张纹理图像,然后,把这两个在空间域的图像信号变换到频域,表示成基本信号的线性组合。PRT选取球谐函数作为基函数进行变换。
PRT 预计算的本质是:对场景中每个点(顶点或纹素),将其在环境光照下的“光传输函数”投影到一组基函数(通常用球谐函数 SH)上,得到一组系数向量。这组系数就是预计算结果。
对于Glossy的情况,如果相机移动会导致出射方向和PRT计算结果不统一,那么相机移动后数据会失效。
3.3.2 PRT Diffuse Case
在绘制方程计算定积分时,BRDF 可以被拆解出来,可以理解为: $$ \begin{aligned} L(\omega_o) &= \int_{\Omega^+}L_i(\omega_i) \cdot f_r(\omega_i,\omega_o) \cos\theta_i V(\omega_i) \mathrm{d}\omega_i \\ &= \int_{\Omega^+}\sum_p[l_p \cdot B_p(\omega_i)] \cdot \rho \cdot \cos\theta_i V(\omega_i) \mathrm{d}\omega_i \\ &= \rho\sum_pl_p\int_{\Omega^+}B_p(\omega_i) \cdot \cos\theta_i V(\omega_i) \mathrm{d}\omega_i\\ &= \rho\sum_pl_p \cdot T_p. \end{aligned} $$ 于是,对于漫反射材质景物表面,根据 PRT 着色表面某一点的运算过程被简化成了向量的点积运算。
- 对于漫反射,使用前三阶的球谐函数便可以得到比较好的近似。
3.3.3 PRT Glossy Case
对于有光泽(glossy)材质的绘制方程,则有: $$ \begin{aligned} L(\omega_o) &= \int_{\Omega^+}L_i(\omega_i) \cdot f_r(\omega_i,\omega_o) \cos\theta_i V(\omega_i) \mathrm{d}\omega_i \\ &= \int_{\Omega^+}\sum_p[l_p \cdot B_p(\omega_i)] \cdot f_r(\omega_i,\omega_o) \cdot \cos\theta_i V(\omega_i) \mathrm{d}\omega_i \\ &= \sum_pl_p\int_{\Omega^+}B_p(\omega_i)\cdot f_r(\omega_i,\omega_o) \cdot \cos\theta_i V(\omega_i) \mathrm{d}\omega_i\\ &= \sum_pl_p \cdot T_p(\omega_o). \end{aligned} $$ 其中 Tp(ωo) = ∑rtp, r(ωo) ⋅ Br(ωo)。
于是,对于有光泽材质的景物表面,根据 PRT 着色表面某一点的运算过程被简化成了向量和矩阵的乘法。
- 有光泽的材质需要用到比漫反射更高阶数的球谐函数;对于学术界,有时用到十阶也仍觉得不够。
4. ShadowMap的原理?有什么缺陷?
Shadow Map 原理
Shadow Map 是一种广泛使用的实时阴影技术,其核心思想是 从光源视角看场景,记录下场景的深度信息,然后在相机视角渲染时,通过比较当前片元在光源空间下的深度与记录深度来判断是否被遮挡。基本流程分为两遍:
- 第一遍:生成深度图 将相机置于光源位置(对于方向光,使用正交投影;对于点光源,使用立方体映射),渲染整个场景,但只输出深度值(不计算颜色),将每个像素的深度(离光源最近的点)存储在纹理中,称为 Shadow Map(阴影贴图)。
- 第二遍:渲染场景并计算阴影 从相机视角正常渲染场景。对每个片元,通过世界坐标变换到光源空间的投影坐标,得到其在该纹理中的采样坐标
(u, v)以及当前片元在光源空间下的深度值d_current。然后从 Shadow Map 中采样出对应位置的深度值d_shadow(即光源下最近点的深度)。- 若
d_current > d_shadow + bias,则说明该片元被遮挡,处于阴影中; - 否则,被光源直接照射,处于光照中。
- 若
Shadow Map 的缺陷
1. 走样(Aliasing)与分辨率限制
- 现象:阴影边缘出现锯齿,或阴影产生“块状”感。
- 原因:Shadow Map 的分辨率有限,一个纹理像素覆盖多个屏幕像素时,边缘采样不足。此外,从光源视角与相机视角的透视差异也会导致采样率不一致。
- 改进:使用更高分辨率纹理、级联阴影映射(Cascaded Shadow Maps, CSM)、方差阴影映射(Variance Shadow Maps, VSM)等。
2. 阴影痤疮(Shadow Acne)
- 现象:物体表面出现自阴影的条纹或斑点,尤其是倾斜表面。
- 原因:深度比较时的浮点误差,以及 Shadow Map 采样点对应的深度与实际表面深度存在微小偏差,导致部分本应被照亮的片元误判为阴影。
- 解决方法:
- 添加深度偏移(depth bias):在比较时加上一个小的固定偏移量(如
d_current + bias)。 - 斜率缩放偏移(slope-scaled bias):根据表面与光源的夹角动态调整偏移量。
- 使用背面剔除(render back faces to shadow map)或正面剔除(render front faces)等策略,但各有利弊。
- 添加深度偏移(depth bias):在比较时加上一个小的固定偏移量(如
3. 透视走样(Perspective Aliasing)
- 现象:离相机近的阴影边缘锯齿明显,而远处的阴影反而平滑,与分辨率限制相反。
- 原因:光源视角下的投影平面与相机视角下的屏幕空间不是线性对应,导致近处的屏幕像素覆盖了 Shadow Map 中过大的区域,采样不足。
- 改进:级联阴影映射将视锥分成多个层级,为近处分配更高分辨率的 Shadow Map,极大缓解了此问题。
4. 软阴影难以直接生成
- 问题:Shadow Map 只能生成硬阴影(完全明或暗),而真实世界的阴影往往有半影区(软阴影)。
- 解决方法:
- PCF(Percentage Closer Filtering):对 Shadow Map 进行多次采样,统计落在阴影中的比例,模拟半影。
- VSM / ESM(Exponential Shadow Maps):基于概率或指数函数近似软阴影。
- 也可结合物理光源大小,进行多次光源采样(区域光源模拟)。
5. 自阴影与物体内部遮挡
- 现象:物体的某些部分(如耳朵、鼻子)会投射阴影到自身,但由于偏移不足可能产生错误的自阴影或缺失。
- 处理:需要精细调整偏移,或使用不同的 Shadow Map 渲染策略(如只渲染背面),但会引入其他伪影。
6. 动态光源与性能
- 对于点光源、聚光灯,每个光源需要独立生成 Shadow Map,开销随光源数量线性增长。
- 动态移动光源需要每帧更新 Shadow Map,对性能影响较大。
7. 阴影边缘闪烁
- 当光源或相机移动时,阴影边缘可能因采样点变化而产生不稳定的跳跃。
- 可通过滤波、时间抗锯齿或级联平滑过渡来缓解。
5. 讲一下PCF和PCSS?
5.1 PCF(Percentage Closer Filtering,百分比渐近滤波)
目的:消除 Shadow Map 采样不足导致的锯齿(硬阴影边缘锯齿)。
原理:
- 传统阴影比较是对单个 Shadow Map 纹素采样,判断是否在阴影中(0 或 1),产生硬边锯齿。
- PCF 在比较时,对当前片元在 Shadow Map 上的多个邻近纹素进行深度比较,计算落在阴影中的比例,然后用该比例作为阴影强度(0~1),实现边缘平滑过渡。
实现:
- 在 Shadow Map 上采样一个区域(如 3×3 或 5×5 的方形),对每个采样点进行深度比较(
d_current > d_shadow + bias),统计通过比较的次数,除以总采样数,得到阴影因子。 - 硬件支持(如 DirectX 的
SampleCmpLevelZero)可高效完成 PCF。
效果:阴影边缘变柔和,但仍然是均匀半影,无法模拟距离导致的软阴影变化。
5.2 PCSS(Percentage Closer Soft Shadows,百分比渐近软阴影)
目的:模拟面光源在真实世界中的软阴影——阴影离物体越远,半影越宽;离接触点越近,阴影越硬。
核心思想:根据遮挡物(投射阴影的物体)与接收面之间的距离,动态调整 PCF 的滤波范围(半影宽度)。
实现步骤:
- 计算平均遮挡深度:blocker search 在当前片元对应的 Shadow Map 区域内(如固定半径)采样多个深度,计算所有深度小于当前深度的遮挡点的平均深度
z_avg。该平均深度代表了遮挡物在光源视角下的平均位置。 - 估算半影宽度 利用相似三角形原理:
半影宽度 = (d_receiver - d_blocker) × 光源大小 / d_blocker其中d_receiver是当前片元到光源的距离(光源空间深度),d_blocker是平均遮挡深度,光源大小是已知参数。 - 执行 PCF 根据计算出的半影宽度,确定 PCF 的采样区域大小(在 Shadow Map 上的纹素偏移范围),对区域内进行 PCF 采样,得到最终的阴影因子。
效果:阴影有自然的软硬过渡——离遮挡物近的区域阴影硬,远离的区域阴影软。
6. 延迟渲染比正向渲染复杂度降低在了哪里?
延迟渲染(Deferred Rendering)相对于正向渲染(Forward Rendering)的核心优势在于将光照计算的复杂度与场景几何复杂度解耦,从而在大量光源和复杂几何的场景中显著降低计算开销。
- 显存带宽:G-Buffer 需要存储多张高精度纹理,内存开销大,对带宽敏感。
- 不支持透明物体:透明物体无法存入单层的 G-Buffer,通常需要单独使用正向渲染混合。
- 抗锯齿困难:G-Buffer 中的边缘难以进行硬件 MSAA,常采用后期抗锯齿(FXAA、TAA)。
- 材质种类受限:G-Buffer 格式固定,难以支持多种复杂的材质模型(需配合 Forward+ 等变体)。
7. 有哪些剔除技术?
7.1 视锥剔除:
分为应用阶段和Clip Space阶段。
应用阶段:
- 位置:CPU 端(或 GPU 端通过 Compute Shader 模拟),发生在 Draw Call 提交之前。
- 操作:使用物体的包围盒(AABB、OBB 或包围球)与视锥体的六个平面进行相交测试。若完全在视锥外,则跳过整个物体的渲染。
- 依据:物体的包围盒在世界空间或视图空间中与视锥体平面做距离测试。
- 特点:
- 粗粒度:只测试物体整体,无法剔除部分在视锥内的物体。
- 可选:由开发者实现,可自由控制精度和策略(如四叉树、BVH 加速)。
- 性能:极大减少 CPU→GPU 的提交量,避免大量顶点被送入管线。
Clip Space:
- 位置:位于顶点着色器之后、光栅化之前,由 GPU 硬件自动完成。
- 操作:
- 裁剪:将跨越视锥体边界的图元(三角形)切割,生成新顶点,使其严格位于视锥体内。
- 剔除:如果图元完全位于视锥体之外(在齐次裁剪空间的所有顶点满足
-w < x < w、-w < y < w、0 < z < w任一条件不成立),则直接丢弃整个图元。
- 依据:每个顶点的 齐次裁剪空间坐标
(x,y,z,w)。经过投影变换后,视锥体被映射为 CVV(规范视景体),剔除条件即是否在 CVV 外。 - 特点:
- 精确:逐图元判断,不会漏掉部分可见的图元。
- 固定功能:开发者无法干预(除非关闭裁剪或使用几何着色器手动处理)。
- 开销:虽然硬件高度优化,但仍会消耗顶点处理后的带宽。
7.2 背面剔除
在屏幕空间做二维叉积,看得到的有向面积的正负。
8. 欧拉角、四元数、旋转矩阵之间怎么转换
8.1 欧拉角->旋转矩阵
R = Ry(α)Rx(β)Rz(γ)
8.2 旋转矩阵->欧拉角
9. 辐射动量学
9.1 各物理量含义
首先这个决定我们看到亮度的能量具体是什么?他并不是灯泡发出的全部能量,我们想象两个不同亮度的灯泡,暗的发光2分钟和亮的发光1分钟耗的电是一样的。【假设电能完全转化成光能】但是这个实际亮度并不一样。也就是说我们看到的亮度并非指这个发出的总能量:Energy,通常用Q表示。
我们可以看到一个2分钟,一个1分钟,和时间有关系,那么看到的亮度是否是单位时间内发出的总能量呢?单位时间内发出的总能量也就是用总能量除以时间,用 Φ 来表示,即 $\Phi = \frac{dQ}{dt}$,t 表示时间。
单位时间内发出的总能量,我们可以用这个量去衡量一个灯泡,也可以衡量他上边一小块面积单位时间内发出的总能量。然后我们遮住其他的地方,只看这一小块的亮度。然后我们选择另外一个大块,也是同样的方式处理,其实对于同一个灯泡,我们看哪一块,不论大小,亮度都是一样的。
但是这俩不同大小的块,单位时间内发出的总能量并不一样,但我们看到的亮度是一样的,也就说明了看到的亮度并非指的是单位时间内发出的总能量。
因此我们要把面积这个因素排除掉,也就是我们考虑单位时间内,单位面积发出的能量记作irradiance,E来表示。$E = \frac{d\Phi}{dA}$,A 表示面积。
这个量是否能够表示我们看到的亮度呢?考虑一个情景,我们如果把一个灯泡换成聚光灯,我们从不同的角度来看这个聚光灯的同一块小面积,其实看到的亮度是不同的,而这一块小面积单位时间发射出的总能量前后肯定不变。两次看的面积又是同一个的,即E相同,但是看到的亮度并不相同。
也就是说我们需要把角度的因素考虑进来,即单位时间内,单位面积,朝着某一个特定的角度发出的能量,记作radiance,用L表示。$L = \frac{dE}{d\omega}$,这里 ω 是立体角。最后这个radiance表示的能量,就能准确的记录我们实际看到的亮度了。
还有一个概念,就是如果不考虑这个灯泡的体积,那么也就没有面积一说,我们从他上边的看到的亮度,应该是取决于:单位时间内,特定方向下发出的能量Intensity,记作I, $I = \frac{d\Phi}{d\omega}$。
这里我们关注一下立体角的微分,在球坐标下可以推出 dω = sin θdθdϕ。
9.2 渲染方程
L(p, ω) 代表radiance。E(p) 代表在p点单位面积接收到的总能量irradiance。二者关系: E(p) = ∫ΩLi(p, ωi)cos θidωi. 二者对立体角求微分,可以得到: dE(p, ω) = Li(p, ω)cos θdω. 这个理解的话就是:E表示单位面积所有方向上接受/发射的能量,而对他的微分就是某一个方向了.
对于渲染方程,其实就是,入射的我们知道了是Li,然后他会和平面作用,然后作用的结果就是Lo了呗。关于和平面作用,其实也就是不变要么打个折,所以也就是乘以一个系数,会根据平面输入和观察方向等等的信息来算出一个系数,其实就是BRDF。 Lo(p, ωo) = Le(p, ωo) + ∫ΩLi(p, ωi)fr(p, ωi, ωo)(n ⋅ ωi)dωi.
9.3 BRDF
什么是BRDF?就是用来表示物体是如何与入射光作用,数值上就表示:朝着观察者方向射出的能量去比上该点各个方向入射的总能量。也就是刚才说的对入射的总能量打几折。
其实通过上边的渲染方程,你应该能对这个量有一个初步的判断,你觉着我上边这句话说的对不对,思考思考。其实我这么说并不严格,宏观上可以这么理解,但是实际上是错的。为什么呢?因为这个fr是一个函数,会随着wi的变化而变化的函数。当我们在上边的渲染方程中积分的时候,是对于dwi进行积分,也就是对每一个入射方向积分,而这些个入射方向之间是不同的。他们有着不同的fr值。
如果只考虑一个入射方向,那么可能你会有这个公式: Lo(p, ωo) = Li(p, ωi)(n ⋅ ωi)fr(p, ωi, ωo). 但事实上有多个方向,因此相当于对 Lo 再求个微分: dLo(p, ωo) = Li(p, ωi)(n ⋅ ωi)fr(p, ωi, ωo). 搞一下除法: $$ f_r(p, \omega_i, \omega_o) = \dfrac{dL_o(p, \omega_o)}{L_i(p, \omega_i) (n \cdot \omega_i)}. $$ 因此对于实际的BRDF定义就如上了。他的意思就是:在某一个立体角方向入射时,单位面积内光线出射的能量比上单位面积内入射的能量。对于分母部分,其实是关于E的一个微分,E表示单位面积上接受的所有能量,对他微分到每一个入射方向也就是这里的分母部分. $$ f_r(\omega_i,\omega_o) = \dfrac{dL_o( \omega_o)}{dE_i(\omega_i)}. $$ BRDF(Bidirectional Reflectance Distribution Function),译作双向反射分布函数,是一个用来描述物体表面如何反射光线的方程,表示了当给定一条入射光的时候,某一条特定的出射光线的性质是怎么样的。它的精确定义是出射光辐射率(Radiance)的微分和入射光辐照度(Irradiance)的微分之比。
10. MSAA怎么做?
MSAA本质上是一种发生在光栅化阶段的技术,也就是几何阶段后,着色阶段前。针对每个光栅化的三角形,遍历每一个像素时,会对MSAA划分的子像素做两个测试:
- 子像素所在depth buffer的深度测试
- 子像素是否在当前光栅化三角形内的测试
如果通过,则将像素的FS得到的颜色填充到子像素的color buffer里。最后对每一个像素内的子像素的颜色做平均。
11. 推导一遍MVP矩阵
Model
先Scale,然后Rotate(按照Yaw->Pitch->Roll顺序旋转),然后Translate。
Scale矩阵: $$ \begin{pmatrix} s.x& 0& 0& 0\\ 0& s.y& 0& 0\\ 0& 0 & s.z & 0\\ 0 & 0 & 0 & 1 \end{pmatrix} $$ Rotate:(注意内旋和外旋顺序相反,即物体坐标系按照Yaw->Pitch->Roll顺序,而写成世界坐标系的话就是相反的顺序) $$ \begin{pmatrix} \cos Y& 0& \sin Y& 0\\ 0& 1& 0& 0\\ -\sin Y& 0 & \cos Y & 0\\ 0 & 0 & 0 & 1 \end{pmatrix} \begin{pmatrix} 1& 0& 0& 0\\ 0& \cos X& -\sin X& 0\\ 0& \sin X & \cos X & 0\\ 0 & 0 & 0 & 1 \end{pmatrix} \begin{pmatrix} \cos Z& -\sin Z& 0& 0\\ \sin Z& \cos Z& 0& 0\\ 0& 0 & 1 & 0\\ 0 & 0 & 0 & 1 \end{pmatrix} $$ Translate: $$ \begin{pmatrix} 1& 0& 0& t.x\\ 0& 1& 0& t.y\\ 0& 0 & 1 & t.z\\ 0 & 0 & 0 & 1 \end{pmatrix} $$
View
作用是将世界坐标系转换到相机坐标系。
https://atri2333.github.io/2025/10/01/games101/
你可以理解为我们要把相机三条轴掰到世界坐标系,然后我们可以先求逆变换,然后做装置 $$ \begin{pmatrix} s.x& s.y& s.z& 0\\ t.x& t.y& t.z& 0\\ -g.x& -g.y & -g.z & 0\\ 0 & 0 & 0 & 1 \end{pmatrix} \begin{pmatrix} 1& 0& 0& -e.x\\ 0& 1& 0& -e.y\\ 0& 0 & 1 & -e.z\\ 0 & 0 & 0 & 1 \end{pmatrix} $$ 这里 g, t, s 分别为观察方向,上方向,右方向。
Projection
正交投影: $$ \begin{pmatrix} \dfrac{2}{r-l}& 0& 0& -\dfrac{r+l}{r-l}\\ 0& \dfrac{2}{t-b}& 0& -\dfrac{t+b}{t-b}\\ 0& 0 & -\dfrac{2}{f-n} & -\dfrac{f+n}{f-n}\\ 0 & 0 & 0 & 1 \end{pmatrix} $$ 透视投影,先考虑将视锥压成长方体: $$ \begin{pmatrix} n& 0& 0& 0\\ 0& n& 0& 0\\ 0& 0 & f+n &fn\\ 0 & 0 & -1 & 0 \end{pmatrix} $$ 然后做正交投影,相乘即可。如果用比较专业的属性:FovY,宽高比aspect,写下来是这样的 $$ \begin{pmatrix} \dfrac{\cot(FovY/2)}{aspect}& 0& 0& 0\\ 0& \cot(FovY/2)& 0& -\dfrac{t+b}{t-b}\\ 0& 0 & -\dfrac{f+n}{f-n} & -\dfrac{2fn}{f-n}\\ 0 & 0 & -1 & 0 \end{pmatrix} $$
12. 为什么我们需要透视校正
我的回答是,在NDC内做重心坐标插值,它到原3D世界坐标系是不对应的,因为从Clip Space到NDC中间做的透视除法是非线性变换。因此透视校正是找到我们要插值的点在原3D世界坐标系的重心插值系数。
杂
1. MVC、MVP、MVVM
MVP相比于MVC,主要差别在于:
- View不再直接持有Model的引用
- Presenter通常和View一比一对应,直接操控View的逻辑
MVVM则更强调数据绑定。例如我更改了Model,Model会带动VM的数据变换,而连带带动绑定的View的数据。如果我改了View,View也会带动ViewModel的数据,继而带动Model。个人感觉MVVM更强调双向的关系。
2. 帧同步和状态同步
Unreal Engine
1. 讲一讲UE的Gameplay架构?
2. 讲一讲UE的反射机制?
我们编辑的是 UBlueprint 资产,编译后得到 UBlueprintGeneratedClass(即蓝图类的 UClass),而 CDO 是该 UClass 的默认对象。
3. UE中Character移动的轴向和靶向的区别?
4. UE的GC?
4.1 核心定位
UE 的垃圾回收系统专门管理 UObject 及其派生类(Actor、Component、Asset等)的内存,不管理普通 C++ 对象(用 new 创建的需要手动 delete)。这套系统让开发者可以在享受 C++ 高性能的同时,获得类似 C#/Java 的自动内存管理体验。
4.2 算法基础:标记-清扫(Mark-Sweep)
UE 使用的是追踪式、精确式、非搬迁式的 GC 算法,核心分两阶段:
标记阶段:从“根集”(Root Set)出发,递归遍历所有被引用的 UObject,标记为“可达”。根集包括全局变量、静态变量、栈上的 UObject 指针、以及通过 AddReferencedObjects 注册的对象。
清扫阶段:遍历所有 UObject,回收未被标记的对象内存,并调用 BeginDestroy() 生命周期函数。
4.3 关键优化机制
1. 增量垃圾回收(Incremental GC) 传统 GC 会在单帧内完成全量可达性分析,造成明显卡顿。UE 5 引入了增量可达性分析,将扫描分散到多帧执行,每帧可配置软时间限制(如 2ms),并通过 TObjectPtr 写屏障在 GC 进行时实时标记被修改的对象引用。
2. GC 簇(GC Cluster) 将相关联的 UObject(如 Actor 及其 Components)聚合成簇,GC 时以簇为单位进行可达性判断,大幅减少遍历节点数。
3. 多线程并行标记 标记阶段可利用多线程并行扫描引用关系,加快标记速度。
4. 分帧销毁(Incremental BeginDestroy) 清扫阶段将 BeginDestroy 和内存释放分散到多帧执行,避免单帧卡顿。
4.4 开发者注意事项
- 必须用
UPROPERTY标记引用的 UObject 指针:否则 GC 会认为该对象无引用而提前回收。 - 推荐使用
TObjectPtr替代原始 UObject 指针:尤其是配合增量 GC 时。 - 避免在 Tick 中频繁创建/销毁对象:改用对象池(Object Pooling),预先分配并复用。
- 手动调用 GC 的时机:可在 Loading 界面等可容忍卡顿的场景手动调用
CollectGarbage,避免在激烈战斗中触发 GC。
5. FInterpTo函数的原理?
1 | /** Interpolate float from Current to Target. Scaled by distance to Target, so it has a strong start speed and ease out. */ |
其实算的就是: Current + DeltaTime * InterpSpeed * (Target − Current).
算法
1. 线性筛法
也叫欧拉筛法。它的核心思想是:让每一个合数被其最小质因数筛到。时间复杂度 O(n)。
1 | bool isnp[MAXN]; |
对于 x,我们遍历到质数表上的 p,且发现 p|x 时,停止遍历质数表。因为:设 x = pr(r ≥ p),这里 p 是 x 最小质因数,那么对于 p′ > p,有 p′x = pp′r = p(p′r),说明 p′x 的最小质因数不是 p′,我们不应该在这里筛掉它。
其次,我们可以保证每个合数都被筛过,设 x = pr(r ≥ p),这里 p 是 x 最小质因数,又设 r = p′r′(r′ ≥ p′),p′ 是 r 最小质因数。在处理 r 时,要遍历质数表,直到遇到 p′ 时结束,所以任意小于等于 p′ 的质数和 r 的乘积,都会在此时被筛掉。
因此对于 p ≤ p′,所以处理到 r 时, rp 一定会被筛掉。
2. 逆元
费马小定理
若 p 是质数,且 gcd (a, p) = 1,则有 ap − 1 ≡ 1( mod p)。
因此快速幂求 ap − 2 即可。
线性递推
设 p = aq + r,即 q = ⌊p/a⌋, r = p mod a。
在模 p 意义下,有 aq + r ≡ 0( mod p)
移项:a = − r ⋅ inv(q)( mod p)。
则 inv(a) = − q ⋅ inv(r) = − ⌊p/a⌋ ⋅ inv(p mod a)
1 | // 多次对不同的p使用需要清空Inv数组 |
3. 迭代版二叉树遍历
主要思路就是用栈来模拟递归。前序遍历和中序遍历可以在访问右儿子前就弹出栈,后序遍历则需要等两个儿子都访问完再弹出栈,需要记录 prev 代表上次弹出栈的点。
前序遍历:
1 | class Solution { |
中序遍历:
1 | class Solution { |
后序遍历,稍微有点复杂,但也没那么复杂,至少是我自己想出来的:
1 | class Solution { |
4. 给定一个0-m的随机数生成器,实现0-n的随机数生成器,n和m大小关系不确定
核心思路:拒绝采样。
采用 m + 1 进制思想,调用 k 次,按进制组合: x = r0 + r1 × (m + 1) + r2 × (m + 1)2 + ⋯ + rk − 1 × (m + 1)k − 1. 这样构造出来的随机数 x 是均匀分布的。然后做拒绝采样即可。
5. 给你一条路,路无限长,路上有n个行人,每个行人有两个特性(速度大小,移动方向),问你怎么求出最先碰面(所有行人中,最先相遇的)的行人的所需时间。
很奇怪找不到原题。但是可以肯定的是,先按照坐标排序,然后求邻近的 n − 1 对行人的相遇所需时间即可。
6. KMP
https://zhuanlan.zhihu.com/p/105629613
妙的是求pmt(next)数组的思想是将自己右移一位和自己匹配。
7. 排序
https://atri2333.github.io/2026/02/23/cpp2/
8. 跳表 SkipList
9. 中位数相关
我们来看以下几类题型
9.1 无序数组的中位数
题目:给定一个未排序的数组,求其中位数(若长度为奇数,取中间元素;偶数,取中间两数的平均值)。
解法:
- 快速选择(Quickselect):基于快排的划分,期望时间复杂度 O(n),最坏 O(n²),可优化到 O(n) 期望。空间 O(1)。
- 堆:建立大小为 n/2+1 的最小堆,遍历数组维护堆,最后堆顶为中位数。时间复杂度 O(n log n),空间 O(n)。
- 排序:直接排序取中间,O(n log n),面试中一般不说。
变形:求第 k 大的数,同样用快速选择或堆。
9.2 两个有序数组的中位数
题目:两个有序数组 nums1 和 nums2,长度分别为 m 和 n,求它们合并后的中位数,要求时间复杂度 O(log(m+n))。https://leetcode.cn/problems/median-of-two-sorted-arrays/
解法:
- 二分查找:在较短数组上二分分割位置,使得左半部分长度 = 右半部分长度(或差 1),且左半部分最大值 ≤ 右半部分最小值。调整分割点直到满足条件,时间复杂度 O(log(min(m,n))),空间 O(1)。
挺难的。
9.3 数据流中的中位数
题目:设计一个数据结构,支持插入整数,并随时查询当前所有数的中位数。https://leetcode.cn/problems/find-median-from-data-stream
解法:
- 两个堆(对顶堆):最大堆维护较小的一半,最小堆维护较大的一半。保持两个堆大小平衡(最大堆大小 = 最小堆大小 或 +1)。插入 O(log n),查询中位数 O(1)。
- 注意:插入时需先根据值决定入哪个堆,再调整平衡。
进阶:若数据量极大且无法全部存储,可用分桶或近似算法(如基于百分位数)。
9.4 滑动窗口中的中位数
题目:给定数组 nums 和窗口大小 k,求每个滑动窗口的中位数。https://leetcode.cn/problems/sliding-window-median
解法:
- 两个堆 + 延迟删除:维护窗口内的元素,用最大堆存较小半,最小堆存较大半。滑动时删除窗口左侧元素,通过哈希表延迟标记,再调整堆平衡。每个窗口查询 O(log k),总复杂度 O(n log k)。
- 有序数据结构(如 Java 的 TreeSet 或 C++ 的 multiset),但需支持重复元素,可直接使用平衡树,插入删除 O(log k),取中位数 O(1)。
9.5 求多个有序数组的中位数
题目:k 个有序数组,总长度 N,求合并后的中位数。
解法:
- 二分答案:对值域进行二分,统计 ≤ mid 的元素个数,调整二分边界。时间复杂度 O(log(max-min) * k * log(L)),其中 L 为单个数组长度。
- 优先队列归并:搞个大小为k的堆,归并到第 (N+1)/2 个元素,复杂度 O(N log k),可接受但非最优。
9.6 中位数贪心
题目:给你长为 n 的数组 a = [a0, a1, ⋯, an − 1],你需要找到数 x,使得 |x − ai| 的和最小。
解法:x 是 a 里的中位数。
证明:https://zhuanlan.zhihu.com/p/1922938031687595039
10. 二分查找
防止面试官让你写出所有开闭区间的情况:
1 | class Solution { |
11. 约瑟夫环
https://leetcode.cn/problems/find-the-winner-of-the-circular-game/
0, 1, ⋯, n − 1 这 n 个数字排成一个圆圈,从数字 0 开始,每次从这个圆圈里删除第 m 个数字。求出这个圆圈里剩下的最后一个数字。
直接讲 O(n) 解法。
首先定义 f(n, m) 表示对 0, 1, ⋯, n − 1 做约瑟夫环操作,最后剩下的这个数字。
注意,每次操作后得到的新序列,数字的排列是有变化的:
- 在 0, 1, ⋯, n − 1 这 n 个数字中,第一个被删除的数字是 (m − 1)%n。为了简单起见,我们把 (m − 1)%n 记作 k;
- 那么删除 k 后剩下的 n − 1 个数字为 0, 1, ⋯, k − 1, k + 1, ⋯, n − 1,并且下一次删除时要从 k + 1 开始计数;
- 相当于在剩下的序列中,k + 1 排在最前面。所以第二次操作的序列是 k + 1, ⋯, n − 1, 0, 1, ⋯, k − 1。
因此再定义 h(n − 1, m) 为在 k + 1, ⋯, n − 1, 0, 1, ⋯, k − 1 做约瑟夫环操作,最后剩下的这个数字。
显然 f(n, m) = h(n − 1, m),我们要做的就是求解 h(n − 1, m),使其能够用 f(n − 1, m) 表示出来。
我们要求的其实是这么一个映射: k + 1 → 0, k + 2 → 1, ⋯, n − 1 → n − k − 2, 0 → n − k − 1, 1 → n − k, ⋯, k − 1 → n − 2
- 该映射 p(x) = (x + n − k − 1)%n。
- 逆映射 p − 1(x) = (x + k + 1)%n。
- 由于映射之后的序列和最初的序列有同样的形式,即都是从 0 开始的连续序列,因此在映射之后的序列上做约瑟夫环操作的结果仍可以用函数 f 表示,即为 f(n − 1, m)。
因此有 h(n − 1, m) = p − 1(f(n − 1, m)) = [f(n − 1, m) + k + 1]%n。
将 k = (m − 1)%n 代入,得 h(n − 1, m) = [f(n − 1, m) + m]%n. 因此可以得到: f(n, m) = [f(n − 1, m) + m]%n (n > 1).
1 | class Solution { |
12. 给出FOV,向前的向量,敌人pos还有玩家pos,写函数判断是否能被敌人看到
先考虑二维平面的情况:
1 | // 判断敌人是否能看到玩家(不考虑障碍物) |
主要原理就是点积算角度,然后看角度是否符合条件,这里直接比较fov半角和玩家与 forward 角度的余弦值,没有问题。
如果是三维情况,则需要定义敌人的前向、右向和上方向。
- 使用敌人的前向(forward)、右向(right)、上向(up)构成右手坐标系。
- 右向可由前向与世界向上的叉积得到(假设世界向上为 (0,1,0),且敌人不会完全垂直朝向)。
- 上向 = 右向 × 前向(再次叉积得到正交的上向)。
设玩家相对于敌人的方向向量为 d,计算 d 在三个轴上的分量。然后计算水平偏角与垂直偏角,分别和 fovX和 fovY比较即可。
1 |
|
13. Lazy线段树(加+乘)
核心idea:先乘后加
添加lazytag的时候同步更新对应节点维护值
1 | const int mod = 998244353; |
14. 逆序对数量
15. 手写个队列?
16. 写个对象池?
17. 二叉搜索树的不同形态数
https://leetcode.cn/problems/unique-binary-search-trees/description/
O(n2) 的dp十分简单,但是这里我们来复习一下卡特兰数。
https://zhuanlan.zhihu.com/p/609104268
它最常用的含义为:
18. 现在有一个函数p概率生成0,1-p概率生成1。实现一个函数50%生成0,50%生成1
我们可以利用这个有偏随机数生成器来构造一个公平的硬币(50% 概率生成 0,50% 概率生成 1)。经典的解法是:
- 连续调用两次有偏函数,得到两个比特
b1和b2。 - 如果
b1 == 0且b2 == 1,则输出 0。 - 如果
b1 == 1且b2 == 0,则输出 1。 - 否则(即
00或11),丢弃结果并重复上述过程。
这样,每次尝试成功的概率为 2p(1−p),且两种输出结果概率相等(均为 p(1−p))。因为每次尝试相互独立,最终生成的 0 和 1 是等概率的。
19. 数位dp
主要解决的是在某个很大范围内求有多少个满足某些数位上的性质的数的个数。
比较好写的方式是通过记忆化搜索,这里以https://leetcode.cn/problems/count-stepping-numbers-in-range/description/ 为例:
1 | class Solution { |
常有的参数就是三个bool值,分别判断是否卡上界、卡下界、前导0。
场景
1. 在一个圆形区域随意生成一个物品
初设计:按照极坐标的想法,分别对离圆心的距离和角度做独立的均匀随机。
这种设计在单位面积上的点数其实是不均匀的。
微积分推导:我们知道,面积的微分 dA = dxdy。而从直角坐标 (x, y) 到极坐标 (r, θ) 的变换为:x = rcos θ, y = rsin θ 。将这个看成是 ℝ2 → ℝ2 的映射,那么得到对应的雅可比矩阵: $$ J = \begin{pmatrix} \cos\theta &-r \sin\theta \\ \sin\theta & r\cos\theta\end{pmatrix}. $$ 那么有 dxdy = |J|drdθ = rdrdθ。面积的微分和 r 成正比,如果你对 r 做均匀采样,那么对于比较大的 r ,它的面积微分也比较大,而在这个微面积内的点就比 r 小的微面积稀疏。
非微积分推导:将圆盘想象为无数个同心圆环。半径为 r 的圆环面积约为 2πrdr,如果半径均匀分布,那么每个圆环被选中的概率相同,但面积大的圆环(外圈)上点的密度自然就小。
再设计:将对离圆心的距离随机采样改成对离圆心距离的平方做随机采样。令 R = r2.
可以推出 $dxdy = \frac{1}{2}dRd\theta$。
其次还是考虑上面每个圆环 2πrdr,为了让每个面积微元被采样到的概率相等,我们就需要让半径 r 的采样概率与圆环面积成正比,即P(r) ∝ r.
2. 游戏中屏蔽字应该怎么处理,用什么算法?
首先屏蔽字有很多,一个一个做KMP肯定不行。因此我们可以“在Trie上KMP”,实际就是AC自动机。
2.1 构建 Trie 树
- 将敏感词词库中的所有关键词插入到一棵 Trie 树中。
- 每个节点代表一个前缀,节点可能携带一个输出列表(表示以该节点结尾的关键词列表,以及可能通过 fail 指针传递的关键词)。
2.2 构建失败指针(fail)
fail 指针 = 当前字符串的“最长后缀 = 另一个模式串的前缀”的位置。和KMP的next数组思路差不多。
- 使用广度优先搜索(BFS)为每个节点计算 fail 指针。
- 根节点的子节点:fail 指针指向根节点。
- 对于其他节点
node,设其父节点为parent,父节点到node的边字符为c:- 从
parent->fail开始,沿着 fail 链查找是否存在一个节点,其子节点也有字符c的边。 - 如果找到,则
node->fail指向那个节点。 - 如果直到根节点都没找到,则
node->fail指向根节点。
- 从
- 同时,为了匹配时能快速获取所有输出,可以将 fail 链上的输出也合并到当前节点(即
node->output包含节点本身的敏感词以及通过 fail 指针传递过来的敏感词)。
2.3 匹配过程
- 从根节点开始,遍历文本的每个字符。
- 对于当前字符
ch,如果当前节点存在ch的子节点,则转移到该子节点; - 否则,沿着 fail 指针回退,直到找到一个节点存在
ch的子节点或回到根节点。 - 每到达一个节点,检查该节点的输出列表,记录所有匹配到的敏感词及位置。
由于 fail 指针的引导,匹配过程不会回溯文本字符,保证线性时间复杂度。
3. 游戏中战力排行榜怎么设计?
无标准答案,我就自己乱想了
初设计:采用B+树,将战力进行有序插入到硬盘数据库中。B+树能够很方便地做区间查询,因为底层叶节点之间是一个链表。在上滚、下滚排行榜时相当于遍历链表然后将信息显示到排行榜上。但是这种不适合实时变化的排行榜。
再设计:纯内存场景下,跳表的范围查询性能往往略优于 B+ 树。例如跳表的更新操作仅影响局部节点和它的索引路径,可以采用细粒度锁(如只锁当前节点及前驱),并发度很高。
4. 几亿数据的排序
切成多个能放到内存中的块,然后分别排序,输出到缓存文件。
然后对这些块,搞个堆做多路归并。
5. 只给一个rand(int x)接口,效果是返回0 - x-1随机数,要求实现在m个玩家中随机挑选n人中奖
第一层是用x进制组合包含剩余玩家的数量的随机数,可能会有拒绝采样。
第二层是随机选择一个人,然后将这个人的id和最后一个人的id交换,然后m–。迭代。
6. 判断A长方体是否命中B长方体。
核心思想是:在三个坐标轴上分别检查两个盒子的投影区间是否有重叠,如果所有轴上都重叠,则相交;否则不相交。
1 | struct AABB { |
如果不是轴对齐的,那么可能需要使用分离轴定理(SAT):
两个凸多面体不相交,当且仅当存在一条轴(单位向量),使得两个多面体在该轴上的投影区间不重叠。 对于 OBB,我们只需要测试有限条候选轴:
- 每个 OBB 的三个面法线(即三个局部坐标轴)
- 两个 OBB 的边方向两两叉积(共 3×3=9 条)
因此最多测试 15 条轴。如果所有轴上投影都重叠,则两个 OBB 相交;否则分离。
当然我自己的想法是:对长方形的12条边分别对另一个长方形做AABB碰撞检测(Slab),但是似乎会漏判。
7. 有64个打字员,8台打字机,至少多少轮能决出前四名?
类似:64匹马,8条跑道,找前4名最少需要多少轮?
简要步骤
- 8 轮小组赛:将 64 人分成 8 组,每组 8 人,每组内决出排名。
- 第 9 轮:每组第一名进行比赛,确定总冠军(设为 A1),并得到各组第一的排名顺序(A1 > B1 > C1 > D1 > …)。
- 候选分析:可能进入前四的选手为 A2、A3、A4; B1、B2、B3; C1、C2; D1。 共 9 人。
- 第 10 轮:让 A2、A3、A4、B1、B2、B3、C1、C2 这 8 人进行比赛,取前三名。
- 第 11 轮:让 D1和上面前三名比,确定2 - 4名。
面试的时候你就这么推。
8. 海盗分金币问题
说是有5个海盗组成了一个舰队,找到了传说中的宝藏。这份宝藏是100枚金币,于是这伙海盗就面临一个分赃的问题,我们知道海盗是非常残忍并且贪婪的。虽然这100枚金币每一枚都价值连城,但海盗们还是依然希望尽可能多地分到金币。
经过一系列协商,最终这5名达成共识,决定采取一种非常残忍的方案。
首先,海盗们会按照功劳大小对五个人进行编号,由编号小的海盗先提出分配方案。如果方案能够得到大多数人(过半)的同意,那么就按照他提出的方案进行分配。如果不能通过,说明他已经失去了威望,海盗们会残忍地将他投入海中喂鲨鱼。
在一个朦胧的早上你一觉醒来,突然发现自己成了一号海盗,那么你应该如何分配才能获得最多的金币,又不会被喂鲨鱼呢?
这就是经典的海盗分金问题。
一个海盗
那么我们从最极端的情况开始,假设只有一个海盗,结论很明显,他独吞所有宝藏。
两个海盗
我们继续,假设有2个海盗,1号海盗和2号海盗,会发生什么?
也很显然,由于题目中说了,每个海盗的提议必须要严格过半,所以无论1号海盗如何分配,2号海盗都一定不会同意。所以1号的结局是确定的,就是被扔进海里喂鲨鱼,即1号必死,2号独吞所有宝藏。
三个海盗
那如果再加一个海盗呢?
再加一个海盗的话,1、2、3号海盗,我们已经知道在有两个海盗的情况下,第一个海盗必死。所以2号海盗无论如何一定会同意1号的方案。
由于每一个海盗都极度聪明,1号海盗也知道这一点。既然无论怎么分配2号都会投同意,那么1号海盗完全可以提议独吞所有金币,这样1号和2号同意,3号反对,同意过半,所以分配方案是[0, 0, 100, 0, 0]。
四个海盗
我们再加入一个海盗,考虑一共剩下4个海盗的情况。
我们已经知道了只剩三个海盗时的情况,所以对于2号海盗来说,如果1号死了,那么他就可以独吞所有的宝藏。所以2号无论如何也不会同意。
当有4个海盗时,需要有3票同意才能通过,所以对于1号来说一定要拉拢3号和4号海盗。通过前面的分析得知,如果1号死了,2号分配,那么3号和4号海盗一无所有。所以1号只需要给3号和4号海盗每人分配1枚金币就可以拉拢他们。
这个时候的分配方案是:[0, 98, 0, 1, 1]
五个海盗
最后我们再加入一个海盗,就达成了题意当中说的5个海盗齐聚的情况了。
首先,5个海盗时需要3张同意票,1号需要拉拢两人投票。如果1号死了,2号可以得到98枚金币,所以2号一定反对。只能从3、4、5号海盗中下手,如果1号死了,2号提议的话,那么3、4、5号海盗的收益是[0, 1, 1]。1号只需要拉拢两人,可以给3号一枚,在4号和5号中挑一人给2枚即可。
所以最终的分配方案是[97, 0, 1, 2, 0]或者是[97, 0, 1, 0, 2]。
到这里,这个问题就结束了。但是我们的思考并没有结束,不知道大家从刚才的解法当中有没有看出规律。我们面临5个海盗这种错综复杂情况的时候根本无从下手,但是当我们倒过来思考,整个推导过程非常简单,而且顺理成章。
如果大家学过算法,想必能反应过来,这其实就是递归算法。
9. 游戏中叉乘和点乘有什么应用场景
10. 如果要做一个编译器工具,来检测循环引用问题,你会怎么做,从编译期和运行时两方面
11. 设计一个算法,随机生成子弹散射的角度,如何实现霰弹枪的散射,生成每颗子弹的位置?
UE的实现
在UE里对应的方法叫做 FMath::VRandCone:
1 | FVector FMath::VRandCone(FVector const& Dir, float ConeHalfAngleRad) |
首先UE取了能够满足球面上均匀采样的 ϕ = cos − 1(2v − 1),其中 u, v 都是 [0, 1] 上的均匀随机采样。
然后将 ϕ 用 FMod 折回到 [0, ConeHalfAngleRad],但这个不是均匀的。
然后根据 Dir 得到旋转。这里 Dir.Rotation() 的含义是:“如果一个物体的前向轴(X 轴)朝向 Dir,那么它的旋转应该是多少。” 通常只从方向向量能确定 Yaw 和 Pitch,Roll 没法从单一方向唯一确定,所以 UE 会把 Roll 设为 0。
1 | // Find yaw. |
从 FRotationMatrix 能够得到以 Dir 为 x 轴的直角坐标系。首先将 Dir 在自己的 y 轴上旋转 ϕ,然后在自己的 x 轴上旋转 θ,得到随机角度。
但是前面提到,ϕ 不是均匀的,所以我会设计一个均匀的做法。
我的实现
1 | FVector UWeaponComponent::VRandCone(FVector const& Dir, float ConeHalfAngleRad) |
原理就是在圆锥底面圆做均匀采样(场景题第一个)
12. 你的项目中的后坐力怎么做的?如何对左右peek视角把后坐力做对?
1 | namespace |
这个函数就是把“相机局部坐标系里的旋转输入”转换成“世界/控制器坐标系里应该加的旋转增量”。
对应你代码的流程(AysPlayerController.cpp):先把 PitchInput/YawInput 组装成 局部旋转(相机坐标系内的 delta)。用 CameraRot 的四元数乘上这个局部 delta,得到 应用局部偏移后的世界朝向。再用“新世界朝向 - 原相机朝向”得到 世界坐标系下的旋转增量,并归一化,最后输出到 AddPitchInput/AddYawInput。
13. 开放世界中随机掉落宝箱,它们的位置是固定的,设计一个算法,实现玩家UI上显示离玩家最近的三个宝箱。
算法设计
1. 预处理:建立网格索引
- 将世界地图划分为边长为 LL 的正方形网格单元格。LL 可根据宝箱平均密度或视野范围选择(例如视野半径的1/2,使得每个单元格内宝箱数量适中,比如10~30个)。
- 遍历所有宝箱,根据其坐标计算所属单元格索引
(cellX, cellY),将宝箱的坐标(或ID)加入该单元格的列表中。 - 存储网格:可用哈希表(稀疏网格)或二维数组(若世界范围有限且可接受内存)。
2. 查询:找到离玩家最近的3个宝箱
给定玩家位置 PP,算法如下:
- 定位玩家所在单元格:
(cx, cy) = floor((P.x - worldMinX)/L), floor((P.y - worldMinY)/L)。 - 初始化:一个大小为3的最大堆(或简单的列表+排序)用于存储当前最近的宝箱(距离、坐标)。初始为空。
- 螺旋搜索:以
(cx, cy)为中心,按曼哈顿距离或切比雪夫距离递增的顺序依次访问单元格。常见的顺序是从半径0开始,逐层向外(类似BFS)。- 对于每个访问的单元格,遍历其中的所有宝箱,计算到 PP 的欧氏距离
d。 - 如果当前堆中不足3个,直接插入;否则若
d小于堆中最大距离,则替换堆顶(即最远的那个),并重新调整。
- 对于每个访问的单元格,遍历其中的所有宝箱,计算到 PP 的欧氏距离
- 剪枝终止条件:当当前已搜索的单元格的最小可能距离大于当前堆中第三近的距离时,可以提前结束。
- 对于当前层(半径 rr),所有未搜索单元格到 PP 的最短距离至少为 (r−1)∗L(r−1)∗L 减去玩家在单元格内的偏移。更精确的剪枝:计算当前已搜索的最外层单元格的边界到 PP 的最短距离。如果该距离 ≥ 当前第3近的距离,且堆中已有3个宝箱,则停止。
- 简化做法:设定一个最大搜索半径(如视野范围),或当搜索半径超过当前第三近距离时停止。
- 返回结果:堆中的三个宝箱即为最近的三个(需按距离升序输出给UI)。